Incremental loading is used to identify new or modified data in the data source since the last time the loading process was executed. Only the new or modified data is copied from the source to the target. This differs from a full load, where the entire data set is loaded into the target. Generally, a full load is required for the initial processing of a new data model. However, when re-processing the model, incremental loading is often used to save time and system resources during the ETL.
In Pyramid, incremental loading is configured via the use of variables. Variables are used to store static or dynamic values that can then be passed into tables for incremental loading, and injected into scripts and filters in the Data Flow. They can also be passed into containers, processes, and dynamic expressions in the Master Flow.
Variables are created from the Variables panel; they can then be referenced in scripts and filters, or used to set incremental loading of tables.
Note: this feature is available only with an Enterprise edition license.
- Click here to learn how to create variables.
Why Use Incremental Loading?
There are several advantages to incremental loading, depending on your data source.
Speed and Resources
Generally, an incremental load will run much faster and uses fewer resources than a full load. Depending on the size of the dataset, incremental loading may be preferable. If the dataset is so large that a full load cannot be completed in the required amount of time, incremental loading is a good solution.
The speed of an incremental load can also be expected to remain consistent over time, because only the new or changes data is copied. If 1,000 new rows are added to a table each day, then a full load will take longer to complete each day, but incremental loading times will remain steady.
Historical Data
Incremental loading is also good for preserving historical data. Say historical data is purged from the data source to free up resources on the server, but report-builders still need to perform data analysis on that data. In an incremental loading system, that historical data remains in the Pyramid data model because it is never overwritten by a full load.
When to Use Incremental Loading?
Although there are advantages to incremental loading, it also adds a layer of complexity to the design of the data flow, and is not always a suitable method of loading data.
There are several circumstances in which incremental loading can be a good solution to implement, including the following examples:
- Your data set is very large, and a full load takes too much time. If the data model is too large to be re-processed according to the required schedule, incremental loading can be used to speed up the process.
- The data set contains columns of sequential data; this is a must, as incremental loading relies on the ability to pinpoint new or updated data.
- You need to keep historical data that is purged from the data source.
Configure Incremental Loading
Incremental loading is configured by passing a variable into a Filter or Query node, and then setting the variable values on the relevant node from the Properties Panel under Set Variable Values.
Step 1: Define the Variable
Create the variable from the Variables panel.
Step 2: Usage
Set the usage for the variable. In the Data Flow, variables can be passed into Filter and Query nodes in order to configure incremental loading.
Step 3: Update the Variable
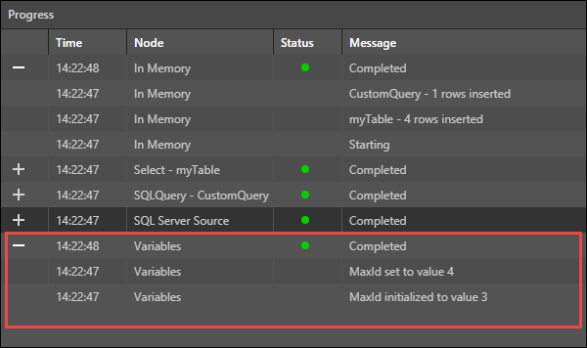
Update the variable from the 'Set Variable Values' window in the Properties panel of the relevant node. The node which is used to update the variable will depend on your specific configuration. You must select the relevant variable, choose the required aggregation type, and select the column in which the incremental loading process will detect new data. This column is often (but not always) sequential, so that the process can identify new or updated rows. A dateKey column is often used for setting incremental loading, but other examples include sequential customer IDs or sequential transaction IDs.
To update the variable, click the relevant node and from the Properties panel, open the Set Variable Values window. To add the variable, click the plus sign to open the pop-up window below:
- Variable: select the required variable from the drop-down.
- Aggregation: the aggregation will determine how incremental loading is applied; it can be set to Max or Min Value, Last or First Value, or Row Count.
- Columns: select the column that will be used to find new data. This column must contain sequential data.
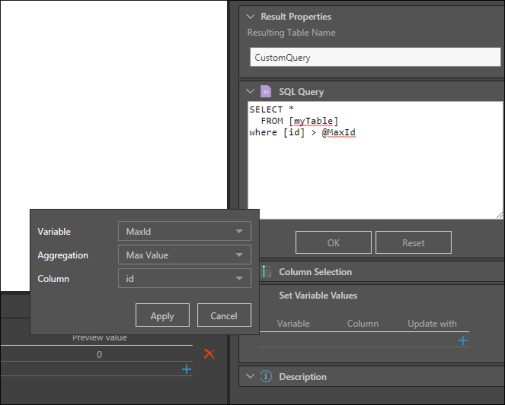
Step 4: Set Writing Type
You can change the writing type of each table in the Data Flow from the Properties Panel of the target node. By default, the writing type is set to Replace but you can change it to Append. This will append the new rows to the table from the previous execution of the data model, rather than replacing the old table with the new one. This can help save time and resources.
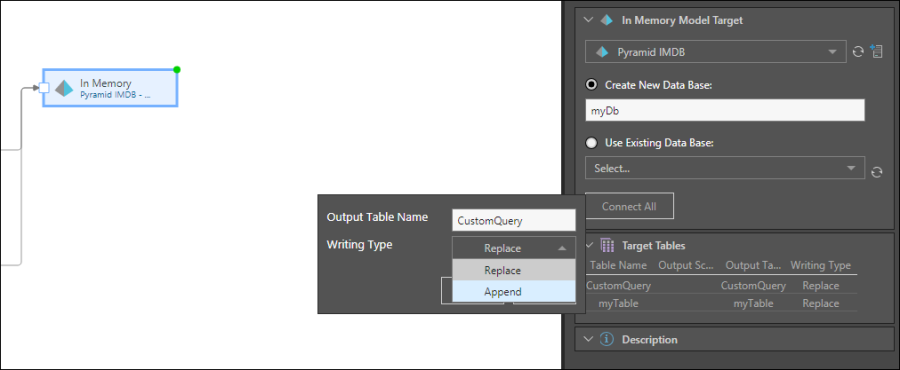
After the data flow or data model has been run, you can access the ETL's Progress panel and see the status of the variables: