The Remove Duplicates node is used to find and remove duplicate rows from the given table. This function is similar to the Distinct node, however, while the Distinct node removes identical rows, the Remove Duplicates node enables users to define duplicate rows according to specified columns. For instance, you may want to remove rows that contain the same customer email address, even if the remaining columns in the rows are not identical.
The Remove Duplicates node will retain the first duplicate row and remove the remaining duplicate rows. For example, say the First Name column is selected as a column to compare, and the column contains three customers with the first name 'Fred'. The last name of each of these 'Fred's is Johnson, Jackson, and Jason. The first row containing 'Fred' will be retained in the First Name column, and the other two will be removed.
By default, only successive duplicates will be removed; if the duplicates in the given column are not in consecutive rows, they will not be removed. To remove non-consecutive duplicates, you must sort the column before removing its duplicates.
How to Configure the Remove Duplicates Node
Connect the Remove Duplicates node to the Select node representing the relevant table. Go to the Properties panel to configure the node:
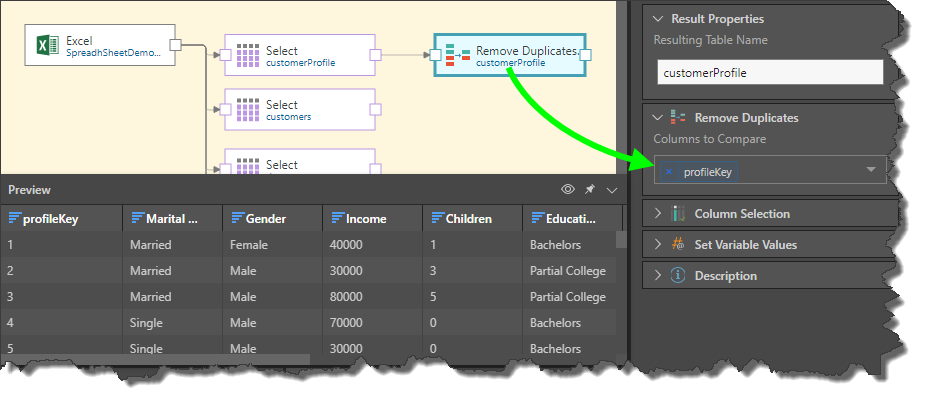
Columns to Compare: choose all the columns from which duplicates should be removed.
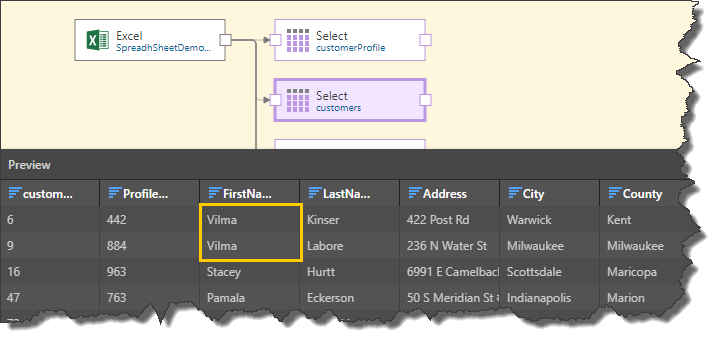
In this example, we see the first 2 rows of the 'FirstName' column contain the same string:
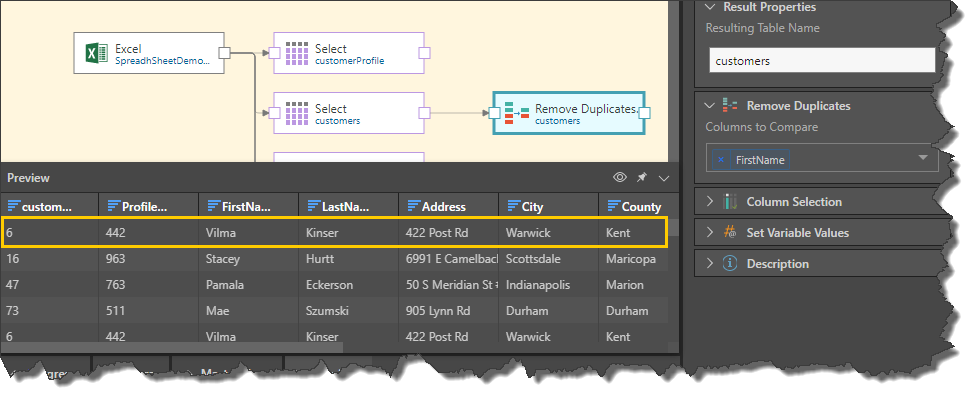
The Remove Duplicates function is applied to the FirstName column to remove the duplicate, leaving only the first of those 2 rows:
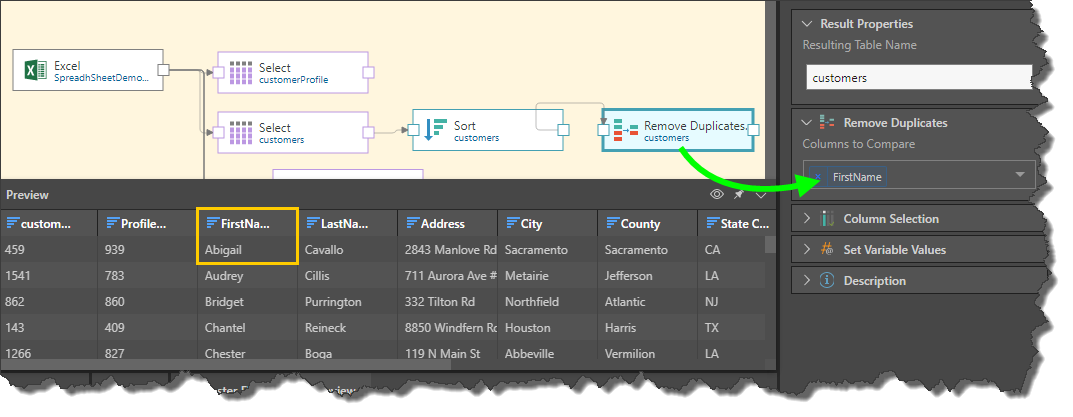
In this example, we have three duplicates in the FirstName column (orange highlight below). However, as we see in the customerKey column (green highlight), these rows are not consecutive:
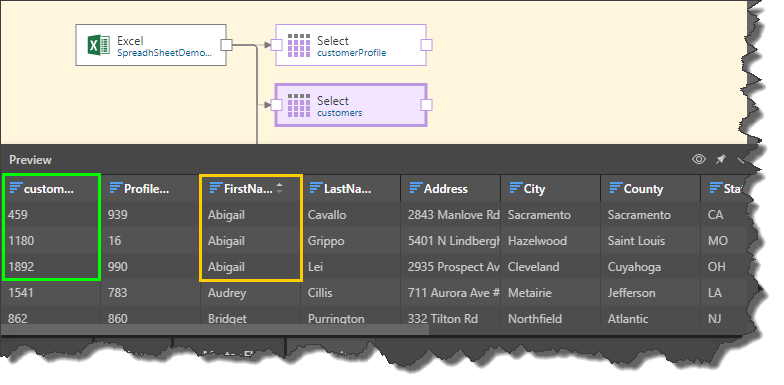
So, the FirstName column is sorted in ascending order to make these 3 rows consecutive:
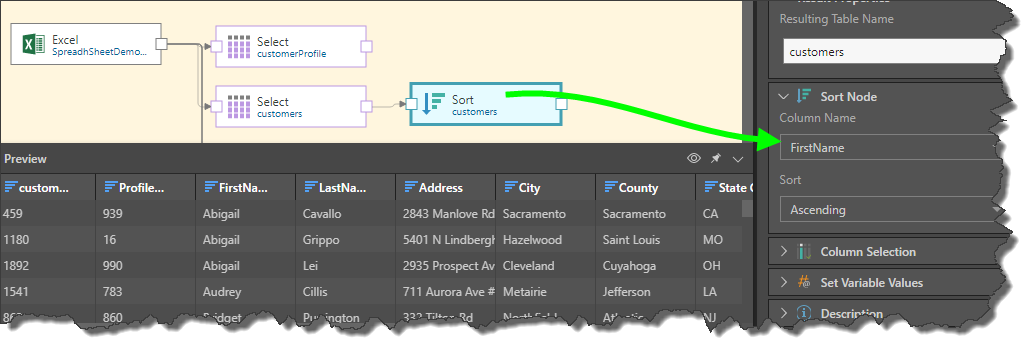
The Remove Duplicates node is then connected to Sort node, and duplicates removed from the FirstName column: