Pyramid IMDB
- Click here to learn how to connect to the IMDB as a datasource.
Configure the IMDB Target
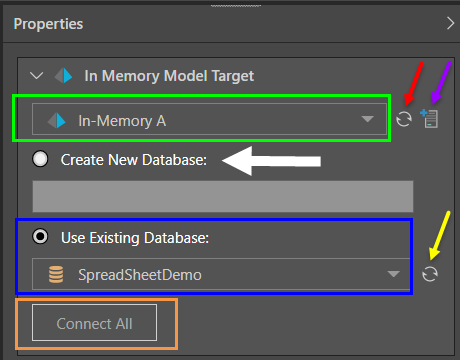
To load the ETL into the Pyramid IMDB, add the In Memory node from the Targets panel to the data flow. From the node’s Properties panel, select the required IMDB server (green highlight below). If the server doesn't appear, try refreshing the list (red arrow), or add a server if you're an Admin (purple arrow).
Next, determine whether to load the ETL into a new database (white arrow), or an existing one (blue highlight).
Finally, click ‘Connect All’ (orange highlight) to connect the IMDB target to the data flow.
Database Selection
To load the ETL into an existing database, select ‘Use Existing Database’, and find and select the required database from the drop-down. You can start typing to search for a database, or click refresh to refresh the list of databases.
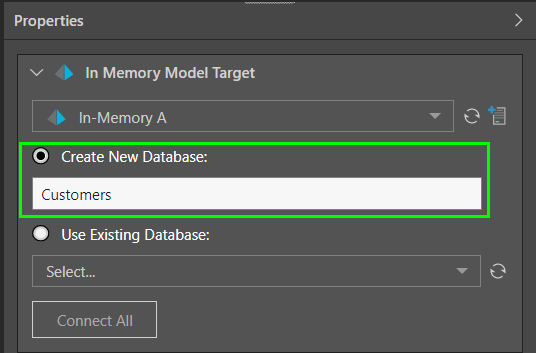
To create a new database and load the ETL into it, select ‘Create New Database’ and provide a name. When the ETL is executed, both the new database and the new data model will be materialized.
- Click here to learn about database and data model materialization.
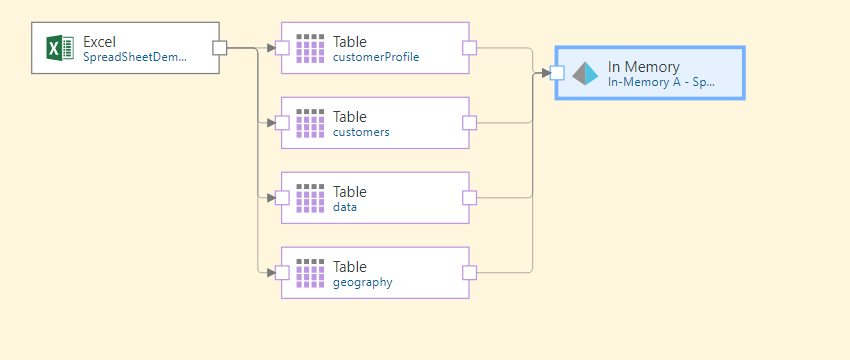
Once you click 'Connect All', the target node will be connected to the data flow:
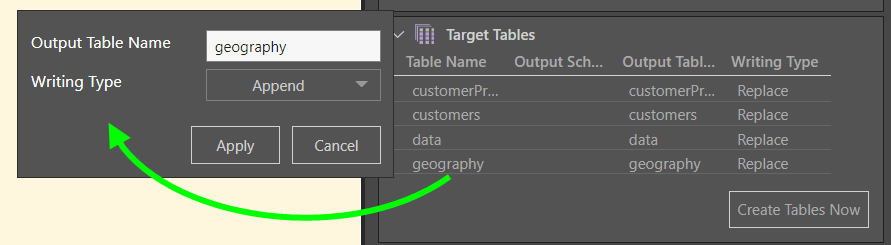
Target Tables
From the Target Tables window, you can rename the table outputs and change the writing type.
- Click here to learn more about target tables.
Description
As usual, you can add a description in the Description window. This is a useful tool for keeping track of the ETL pipeline, especially if multiple users will be maintaining the model.
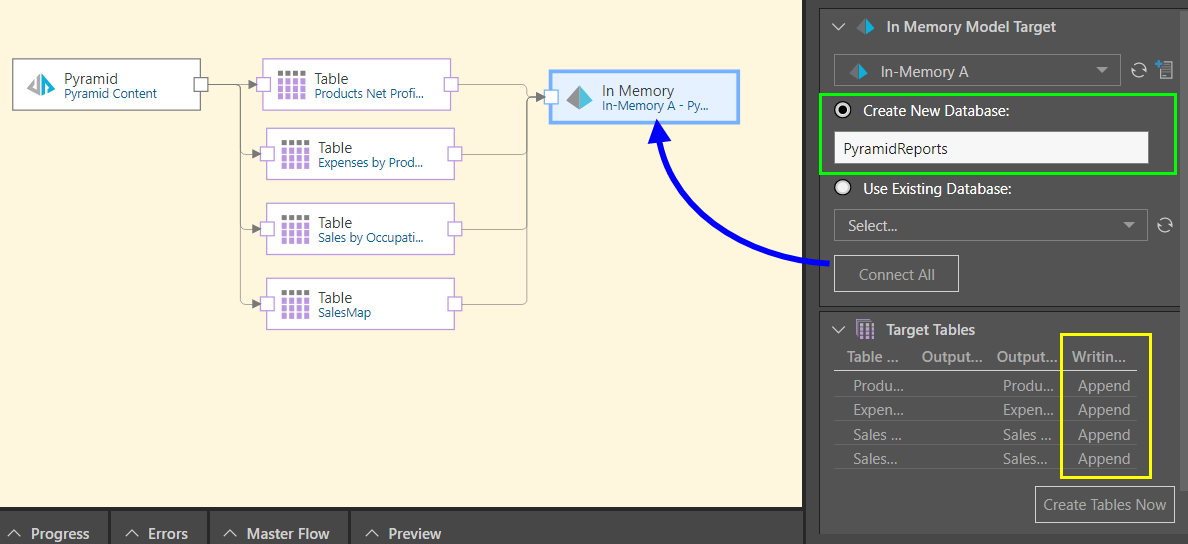
In this example, the Pyramid Content source node was used to convert selected Pyramid reports into tables. The ETL was then loaded into an IMDB target, where a new database was created (green highlight below).
The writing type for each table was then changed from Replace to Append (yellow highlight) to save on time and resources when the ETL is re-processed.