Relational Targets
Pyramid supports use of the following relational databases as targets. You can load your ETL into any of these databases:
- DB2
- DB2 AS400
- Exasol
- MySQL
- Oracle
- PostgreSQL
- SAP Hana
- SAP IQ
- SQL Server/ Azure
- Teradata
- Netezza
Connect the Target
Next, decide whether to create a new database within which to store the new model (white arrow) , or store the model in an existing database (green highlight).
Database Selection
To load the ETL into an existing database, select ‘Use Existing Database’ and select the required database from the drop-down list. The new materialized model will be stored in the given database.
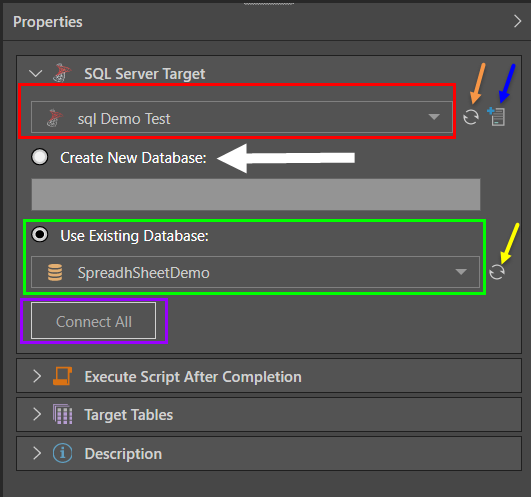
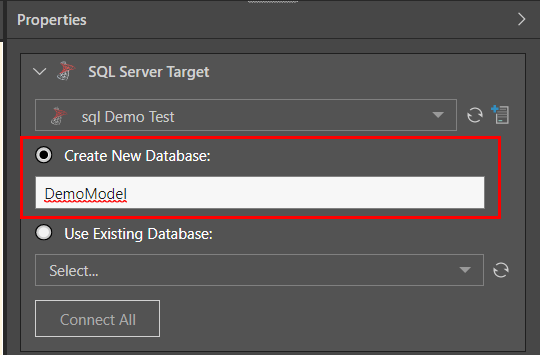
To create a new database, select ‘Create New Database’ and provide a name. When the ETL is executed, both the new database and the new model will be materialized.
- Click here to learn about database and data model materialization.
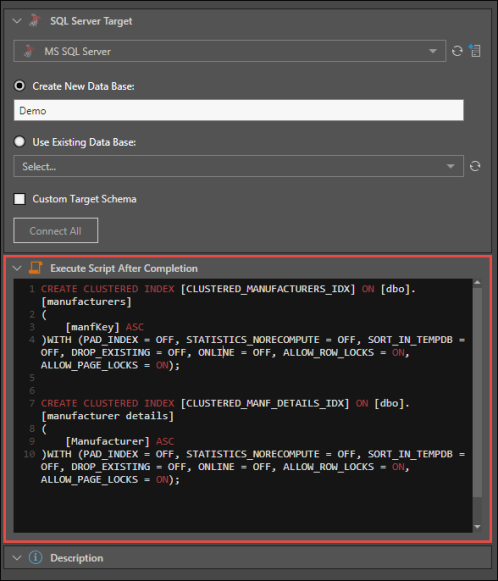
Execute a Script for SQL Targets
When using an SQL target (SQL Sever/ Azure, PostgreSQL, or MySQL), an additional window appears in the target's Properties panel, 'Execute Script After Completion'. Expand this window to expose the script editor, where you can construct an SQL script which will be executed after the ETL has run.
- Click here to learn more about executing a script for SQL targets.
Target Tables
From the Target Tables window, you can rename the table outputs and change the writing type.
- Click here to learn more about target tables.
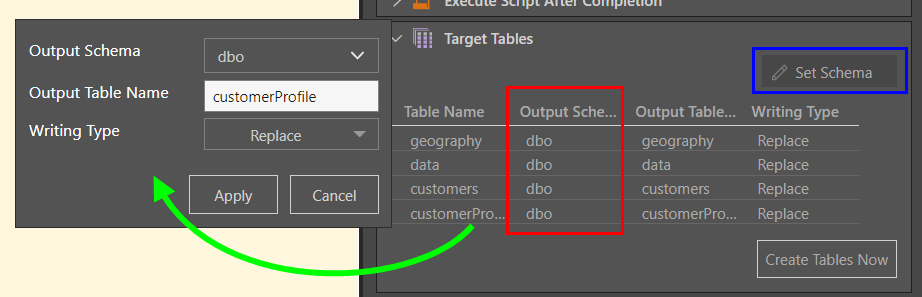
Custom Target Schema
The 'Set Schema' option (blue highlight above) enables you to set a custom target schema for the entire model or for specified tables, rather than the database's default schema. This option is supported for the following target databases only: SQL Server, SQL Server Azure, PostgreSQL, SAP HANA, DB2, Redshift, and Snowflake.
- Click here to learn more about setting a custom target schema.
Description
As usual, you can add a description in the Description window. This is a useful tool for keeping track of the ETL pipeline, especially if multiple users will be maintaining the model.
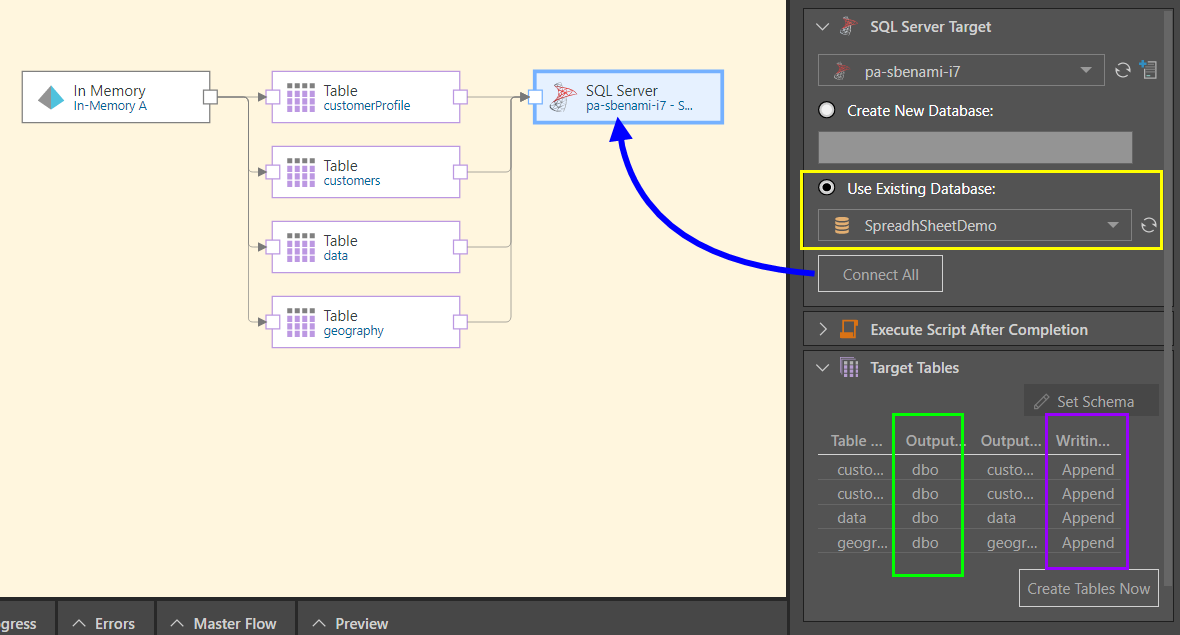
In this example, tables were copied into the data flow from an IMDB source. The ETL was then loaded into an SQL Server target, on an existing database (yellow highlight below).
Next, the writing type was changed to Append (purple highlight) and the custom target schema set (green highlight) for all target tables.