Model processing is required to produce a live data model from the model definition file. The data flows and models designed in the Model app are stored in a model definition file, which is saved in the content management system. In order to produce or materialize a database, data model, or machine learning model, the definition file must be run. Once the model definition file is materialized, the live data model that is produced can be queried from the other Pyramid modules.
Model processing can also be scheduled on a regular basis to ensure the model is updated with the most recent data.
- Click here to learn how to schedule data model processing.
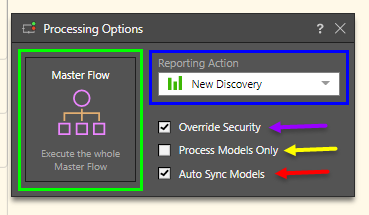
Processing Options Dialog
Open the model in the Advanced Data Flow and click the Pyramid execute button  from the top left-hand corner. In the Processing Options dialog, select whether you which ETL component to execute.
from the top left-hand corner. In the Processing Options dialog, select whether you which ETL component to execute.
Master Flow: (green highlight below) process the entire master flow and all of its components.
Reporting Action: (blue highlight below) choose which module the new data model should be opened in: Discover, Smart Discover, Smart Publish, or Smart Present. The data model will open in the given reporting tool immediately after processing is complete. If you don't want any reporting tool to open automatically, select None.
Override Security: (purple arrow below) enable to override metadata security set from the Admin console or the Materialized Manager. Disable if metadata security should not be affected by processing the data model. Click here to learn more.
Models Only: (yellow arrow below) save and process the model(s) only, without saving the data flow or master flow.
Auto Sync Models: (red arrow below) automatically update models that were previously processed.
If you haven't already saved the model definition file, you'll be prompted to do before processing begins.
You can view the progress dialog from the job spooler, in the bottom right corner:
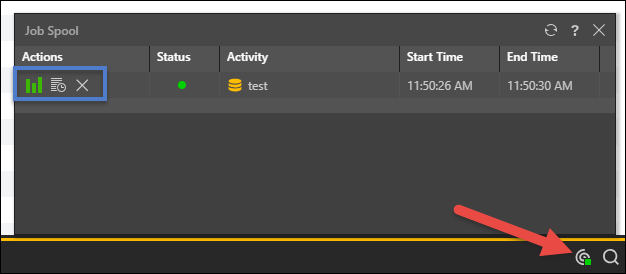
Under the Actions column of the model execution job, you can:
- Open the data model in Discover
- Open the job's ETL Progress dialog
- Remove the job from the spooler
Reprocess a Model
The model should be reprocessed if any changes are made to the Master Flow, Data Flow, Data Models, or Security. Changes made to the model definition file will only be seen in the materialized objects if the model is reprocessed.
Models should also be reprocessed to ensure they are kept updated with the latest data. You can reprocess a model manually, by processing from the Processing Options dialog (as described above). Model reprocessing can also be automated via model scheduling.
- Click here to learn about schedule model processing.
Manage Security
Roles are assigned read and write permissions from the Security panel. These security permissions are saved to the model definition file, and automatically applied to the materialized data base and data model once it is processed.
Security for materialized live data bases and data models can then be managed in two places:
- Materialized Manager in the CMS: assign roles to servers, and materialized live data bases, and data models. Here you can assign read or write permissions only - you cannot manage metadata security and overlays.
- Source Manager in Admin: assign roles to servers, data bases, and data models. Roles can also be assigned to metadata in each materialized live data model, enabling you to define which roles can and can't see given hierarchies, members, and measures. Assign given roles to hierarchy and member overlays.