Connect to SFTP (SSH) or FTP to copy Text, JSON, XML, and Excel files and convert the data into tables.
The FTP node lets you connect to your regular File Transfer Protocol (FTP) or to you secured File Transfer Protocol (FTPS), depending on the server configuration. The SFTP (SSH) node lets you connect to your Secure File Transfer Protocol (SFTP), which uses Secure Shell (SSH) to transfer files securely.
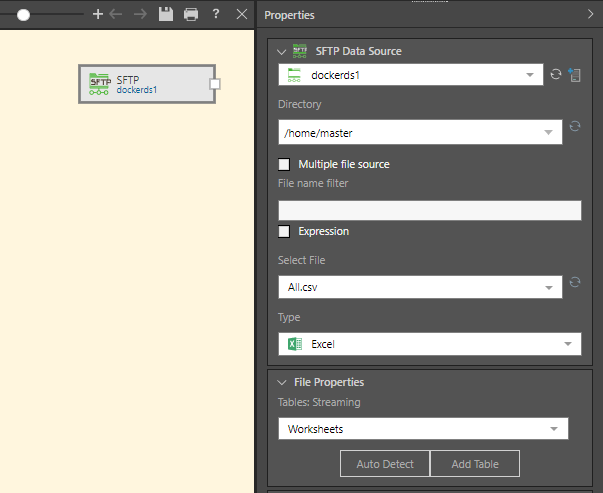
SFTP Properties
With the SFTP or FTP node selected, configure the node's properties:
- Directory: choose the SSH directory from the drop-down, or write or paste the directory.
- Multiple file source: enable this option is you want to import multiple files of the same type. Each file must have the same structure (columns) and file type (i.e. Text, JSON, or XML).
- File name filter: enter a file name to filter the found files in Select File drop-down.
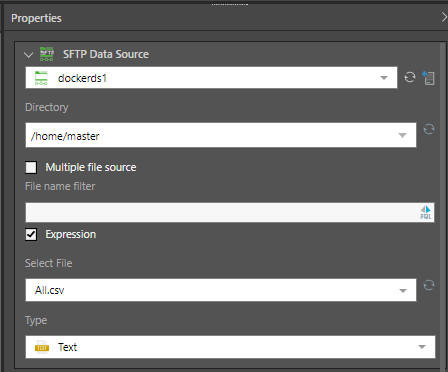
- Expression: enable to expose the PQL editor, where you can write a PQL expression to be injected into the file name filter field.
- Select file: select the file to be added to the Data Flow. If the 'Multiple file source' is enabled, all files in the given directory will be selected and listed in the Found Files window.
- Type: choose the file type; this must match the file type of the selected file.
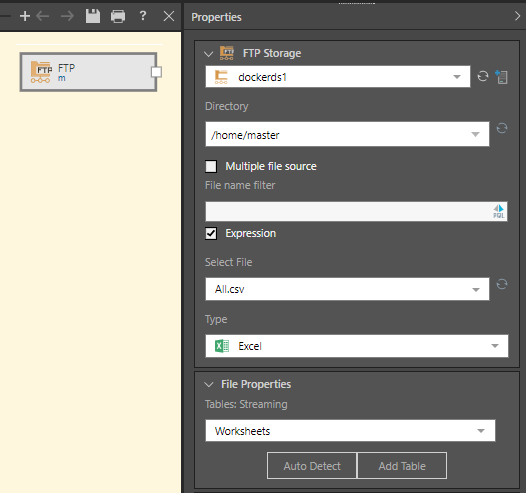
File Properties
Once you've uploaded or connected to the file, you'll need to configure the properties to determine the structure of the table. Follow the links below for details on configuring the file properties for each file type:
Table Selection
The file will appear as a single table in the Tables window; select the table and click the 'Add Table' button.
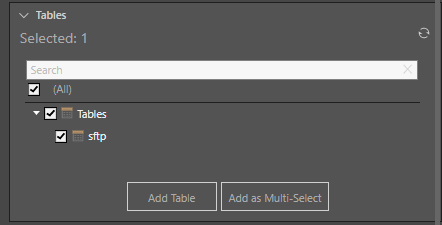
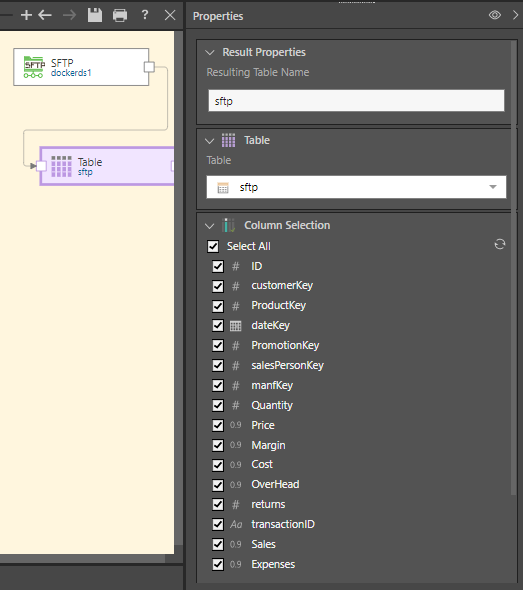
The table will be added to the data flow and connected to the source node:
Description
Expand the Description window to add a description or notes to the node. The description is visible only from the Properties panel of the node, and does not produce any outputs. This is a useful way to document the ETL pipeline for yourself and other users.
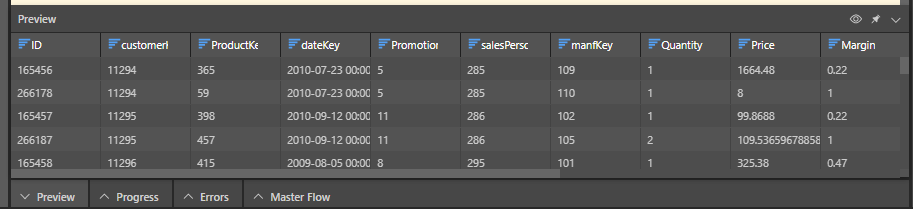
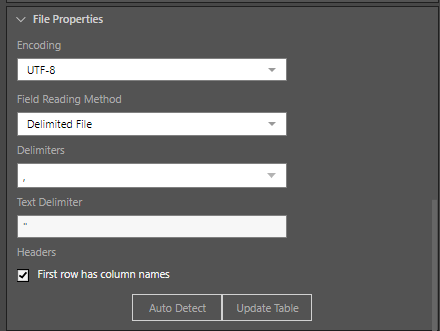
In this example, the SFTP node was added to the Data Flow and used to convert a .csv to table, using the Text file type:
Once the file is selected, the file properties must be set. Because this is a comma separated file, the reading method is set to 'Delimited File' and the comma delimiter is selected. And as each column contains a header, the 'First row has column names' option is enabled:
Pyramid connects to the file and converts it into a table, which is then added to the data flow using the Add Table function:
When we preview the table in Pyramid, we see that the CSV file has be converted correctly: