Pyramid allows administrators to add their own custom JDBC data drivers to the platform to access data sources that are not supported by the system out of the box. This capability effectively allows customers to connect to their own bespoke data sources at their own discretion.
Custom drivers or connectors require administrators to ensure the driver is compatible with the version of Java used in Pyramid and that is licensed appropriately.
Pyramid takes no responsibility for the operation, functionality or performance of custom drivers.
The custom JDBC connector is not available in the Community Edition.
Capabilities and Limitations
Custom connectors can be used for data ingestion and Direct Query models.
While Direct Query models may be built using Custom Connectors, Pyramid cannot guarantee full operational functionality when queries are run. Pyramid will not offer support for Direct Query models built using Custom Connectors.
The data, when ingested into the platform through the data flow and modeling tools, should be extracted and written to a sanctioned data source target supported by Pyramid. In general, it is assumed that the connector can accept ANSI SQL commands within this context for reading data tables and rows. However, using the custom query node in the data flow toolset, it may be possible to write any supported query syntax supported by the JDBC driver. You will need to consult with the driver's documentation for this type of functionality.
Note: Custom connectors cannot be used as a target data system to write data back to.
Adding a Custom Connector
Click Add Custom Connector (red highlight below) to open the Add Custom Connector panel, where you define the properties of the custom connector and upload the driver JAR file. The JAR files can be downloaded from the vendor's site or in some cases from Pyramid's marketplace (see below).
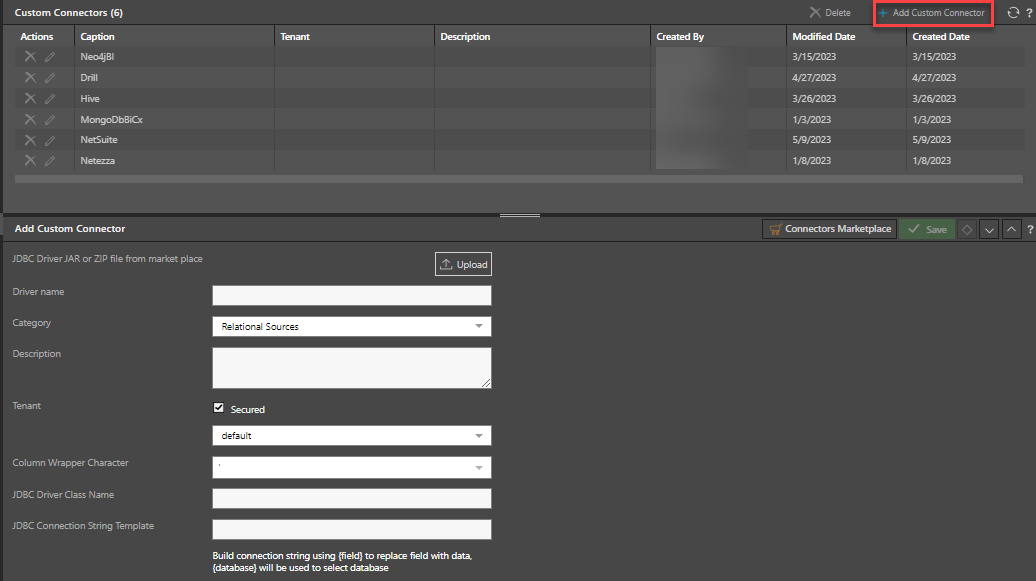
Connector Marketplace
Pyramid should be able to support any compatible JDBC driver that works with the currently deployed version of Java. To make access to drivers simpler, users can click the marketplace button Connectors Marketplace to access a listing of several JDBC drivers not included in the installation by default and 200+ JDBC drivers provided by CData - a technical partner of Pyramid.
Besides the CData driver listing, the following driver packages can also be downloaded from the marketplace:
- Amazon Athena - Two versions of the Athena custom connector are available in the marketplace. You can use either version, but not both.
- Apache Drill
- Apache Hive
- ClickHouse
- Cloudera Impala
- Databricks
- Dremio
- MySQL*
- IBM Netezza
- MongoDb BI
- Neo4J BI Connector
- Neo4J Cypher
- Oracle NetSuite
- SparkSQL
* The version of MySQL from the marketplace is the original GPL driver. Regular MySQL connections use the MariaDB driver.
Note: These drivers should not be unzipped after being downloaded. The entire zipped package should be uploaded.
Uploading a Custom Connector
The Custom Connector manager allows admins to upload and configure the JDBC driver file (or package). This includes:
- Driver - Upload the JDBC JAR file to the system
- If the setup requires a collection of JAR files, place the files into a zip file and upload that instead.
- Name - provide a name for the connector (as it will appear to end-users in the application)
- Category - choose a category for your driver to make it easier for end-users to find it in the data source lists.
- Description - provide a meta description for the connector
- Tenancy - this allows admins to decide if the specific driver should be accessed by all tenants on the platform or be limited to the selected tenant.
- Column Wrapper - select which character is used by the driver (and data source) to designate columns from the dropdown list
- JDBC Class Name - provide the namespace and class name of the driver as it should be used in Java code (see below)
- JDBC Connection String Template - provide the template string for how to connect to the data source with the driver (see below)
- Data Source Type - select a source type classifier from the dropdown list. This merely organizes the new connector into the right grouping inside the data modeling tools.
Class Names
The JDBC class name is critical to the operation and its use in the Java back end. The class name is a technical string that will be provided in the documentation of the chosen driver. In some situations, the class name can be auto derived from the uploaded JAR files. In this case, Pyramid will auto populate this for you.
- For MySQL: com.mysql.jdbc.Driver
- For SnowFlake: net.snowflake.client.jdbc.SnowflakeDriver
- For CData's Zendesk driver: cdata.jdbc.zendesk.ZendeskDriver
Direct Query
Administrators can elect to make the custom connector enabled for direct querying. This is done by clicking the enabled checkbox and choosing a "SQL style" based on another curated database technology style from the dropdown list (yellow box below).
The SQL style informs the query engine of the syntax and query structure style that best suits the custom data source.
WARNING: Custom connectors are NOT fully curated by Pyramid. So their performance and compatibility cannot be fully vetted or checked. Querying the source directly may produce errors and there may be functional incompatibilities between what one is able to do in Pyramid and what the data source can support. If enabled, administrators should ensure that the data source is configured and resourced to handle multiple concurrent requests from users as they analyze its data directly. Ultimate responsibility for a direct connection and its functionality therefore lies OUTSIDE the domain of the product.
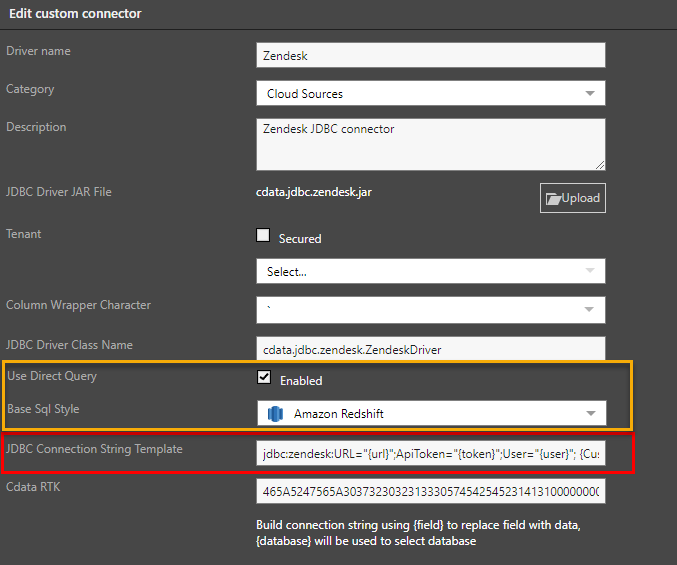
Connection String Templates
Each uploaded driver will have its own unique way of connecting to the data source. This is expressed through the connection string. As such a template for this connection string must be provided as part of the configuration (red highlight above). The connection string style should be provided by the JDBC's own documentation.
To ensure the template is dynamic for end-users, any values that should be injected into the connection string when it is used should be provided as "fields" - which are strings enclosed in braces "{........}". These will also instruct the user in how to supply the necessary details for connection when it is accessed in the data source manager.
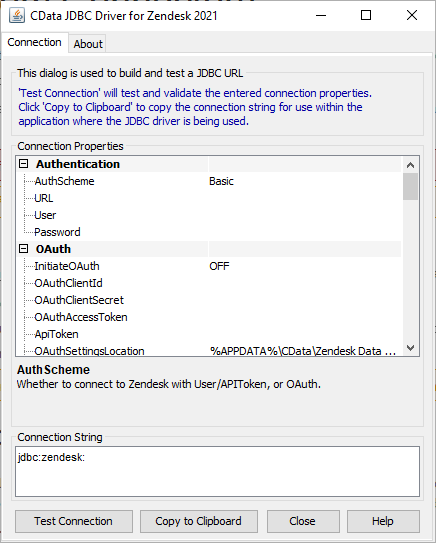
To check which parameters are available to be used as a connection string, you can double click the JAR file from its folder location (before uploading to Pyramid); you'll see all the connection properties that can be sent via the JDBC connection string in Pyramid.
Connection strings can be hard coded or made editable. A hard coded connection string will be saved as part of the JDBC driver in Pyramid, and the user won't be able to edit per data source.
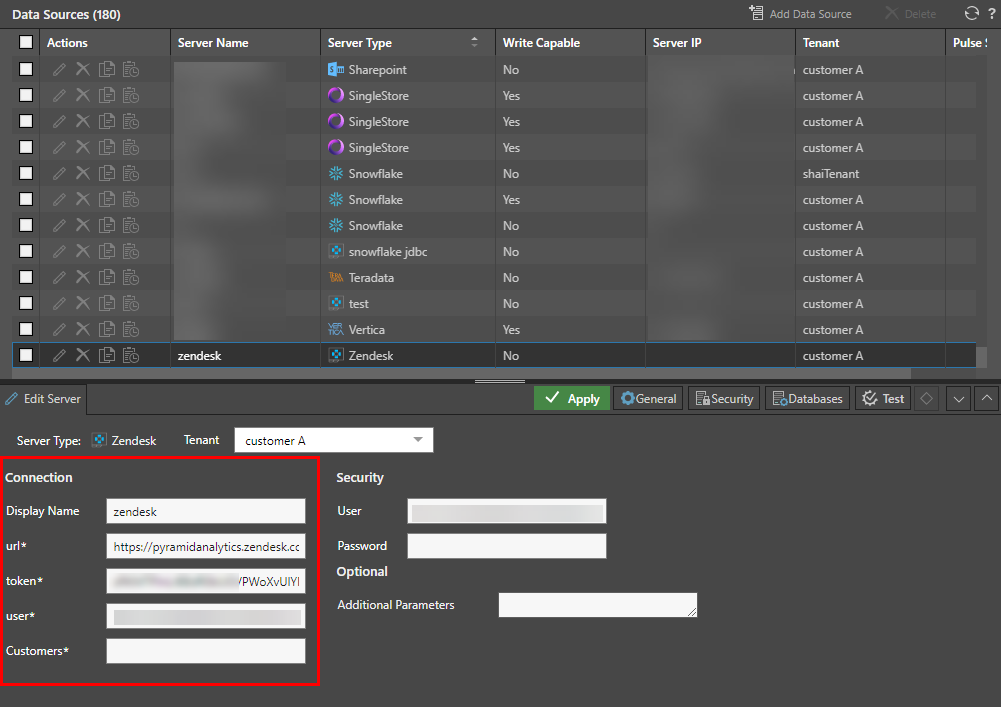
Connection strings that are not hard coded can be edited per data source from the Data Source listing. The given properties will appear under "Connection" (red highlight below); enter the relevant value for each field.
Template String Examples
Connection string templates that are wrapped in braces { } can be edited per data source from the Data Source listing.
MySQL
jdbc:mysql://{address}:{port}/{database}
- By putting address, port and database in braces, the system understands that an end-user is required to provide 3 pieces of information for the connection to succeed and will be prompted as such.
SnowFlake
jdbc:snowflake://{account_name}.{region}.snowflakecomputing.com/{database}?warehouse={warehouse}
- Here the end-user will need to supply account_name, region, database and warehouse details.
CData Zendesk
jdbc:zendesk:URL="{url}";ApiToken="{token}";User="{user}";
- Here the user needs to supply a url, api token and a user name.
When the connection string is not wrapped with braces, it is hard coded, meaning it cannot be edited per data source. In the following examples, the database name is hard coded, so users will not be able to edit the database name per data source.
SQL Server
jdbc:sqlserver://ip:123;databaseName=databaseName;
PostgreSQL
jdbc:postgresql://ip:123/databaseName?OpenSourceSubProtocolOverride=true
SAP
jdbc:sap://ip:123?instanceNumber=90&nativeAuthentication=yes&databaseName=databaseName
Managing Connectors
Admins can easily click on any existing connector to edit its settings or replace the drivers files. Similarly, connectors can be deleted from the platform.