Use the data model manager to manage the model, set model security, and manage model elements and security (hierarchies, measures, levels, and members).
- There is an equivalent tool for non-admin users called the Materialized Data Manager. The Materialized Data Manager enables some of this functionality for end-users who own data models.
Tip: This topic describes data source Model management. For information about managing your Servers and Databases, see Data Source Servers in the Admin Console and Database Management in the Admin Console, respectively.
General
Use the server tree on the left to find and select the Data Model you wish to manage. For more information about Filtering and Sorting this tree, see Server Tree.
Once you have the Model selected, you'll see the following items on the General tab:
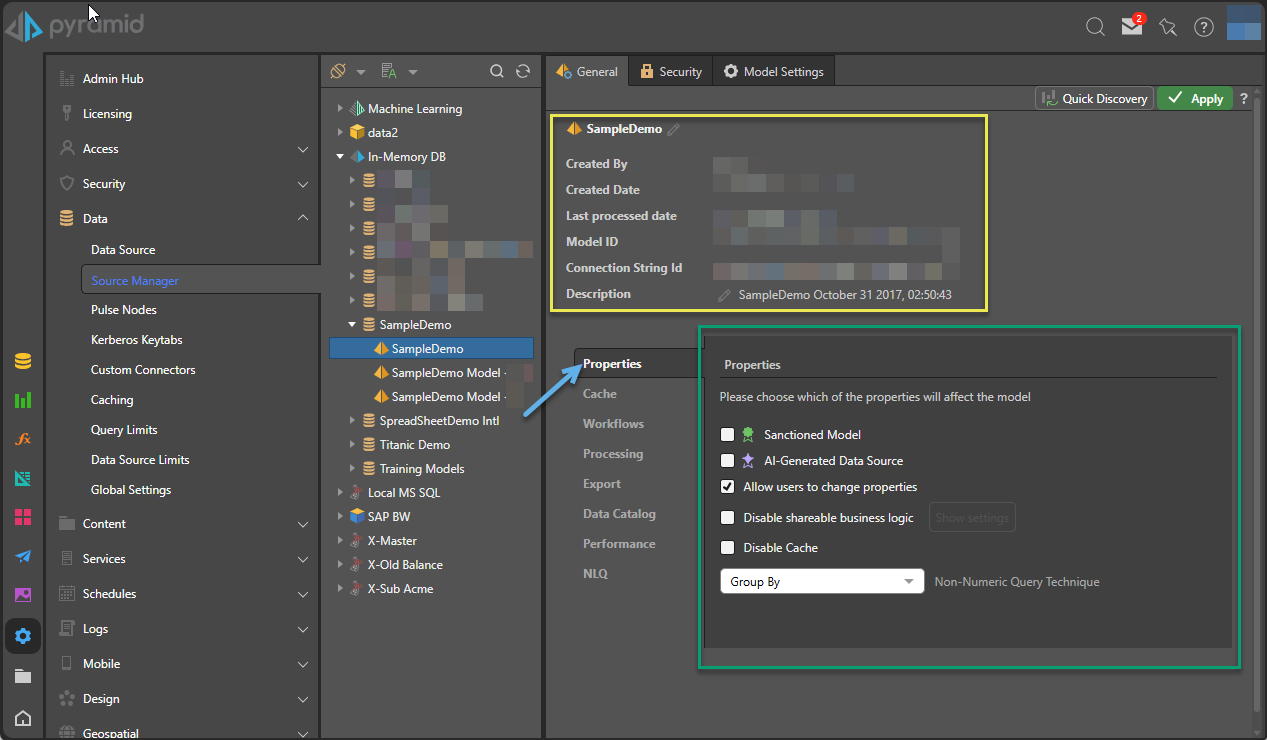
Quick Discovery
When you are viewing your Model's General details, you can click the Quick Discovery button at the top-right of the page to create a new, empty, discovery in the selected Model. This allows you to get modeling right away, without having to open Discover, select a model, and so on.
- Click here for more information
Model Metadata
The Model Metadata (yellow box above) is specifically related to the Meta-structure:
- Created by: The user who created the data model.
- Create Date: The date the data model was initially created.
- Last Processed Date: The date the data model was last processed.
- Description: Any description added by the designer.
Properties, Settings, and Actions
The blue arrow in the preceding image drives the menu, and the green box shows the location of the settings or actions.
Properties
All model types:
- Sanctioned Model: Select this checkbox to mark the data source with the Sanctioned certificate. This certificate appears next to the data model's name when it is opened in Discover, Formulate, or Present. This is a useful way to indicate to users which data models have been verified and reviewed. Note: this feature is not available in the Community Edition.
- AI-Generated Data Source: Select this checkbox to mark the visuals associated with this data source with the AI-Generated Icon in Discover, Formulate, or Present. This is a useful way to indicate to users which data models contain AI-Generated Content. For more information, see Identify AI-Generated Data Sources.
- Allow users to change properties: Select this option to allow users to change the metadata overlay properties.
- Disable shareable business logic: Select this option to disable the creation of sharable business logic (formulas, lists and parameters) by end users. Click Show Settings to select the user roles for which shareable business logic will be disabled.
- Click Audit Trail to open the audit trail to see all changes made to key objects throughout the system.
SQL data sources only:
- Disable Cache: Disables the Cache.
- Non-Numeric Query Technique: choose the preferred query technique to return a distinct list of attributes for non-measure queries (such as slicers or element lists). The default query technique is "Group By"; but in some cases, the "Distinct" technique is faster. Some data sources, like SQL Server, are able to determine the fastest technique and apply it at runtime, but some data sources do not have this ability. In this case, you can set the default to Group By or Distinct.
- Group By: this is the default option, and is the only option that can be used for queries that include measures.
- Distinct: selecting this option may improve performance in queries without measures, depending on the data source.
MS OLAP, Tabular, SAP BW, and Hana (where Hana has a Semantic layer only):
- Data model has NO data-level security: By default, caching is disabled for MS OLAP, Tabular, SAP BW, and HANA models, to ensure that data-level security is not violated. If you DO NOT have data-level security in the cube, you can check this option to enable caching. Selecting this option means you also need to clear the Data model uses real-time direct queries or ROLAP checkbox.
- Ignore cube-action access security for cells: By default, cube actions are secured. Disabling this will lighten the action engine load and improve performance.
- Disable the Show Details action: Allows switching off of the MS SQL Server Analysis Service option to Show Details (using the SSAS Cube defined "drill through").
- Data model uses real-time direct queries or ROLAP: if the data model uses ROLAP, you can check this option to forcibly disable all caching if you want to ensure that the query results are up to date (real-time), rather than cached.
MS Tabular data sources only:
- Data model has attribute-access security: All other data sources have a single model that is consistent across all users. Any security that is user dependent is done on the data itself, and not the model. Tabular, however, allows security to be added to the model. This option tells Pyramid that this tabular instance does in fact have model security, and that Pyramid must retrieve a model per user.
SAP BW data sources only:
- Element listings should use Default Measure: By default, on retrieving a simple list of elements in a slicer, elements tree, or grid with a single attribute on it, we create a dummy measure in the query. There are some models in BW that may react more quickly if instead of using that "dummy measure" we instead use the default measure as defined in the model. This flag is used to tell Pyramid to use that default measure.
Cache
- Clear Meta Cache: clear the metadata cache for the current data model. This cache holds metadata related to database structures and models, extracted for queries. Caching metadata can have a significant positive impact on performance and should be used. It should be used with at least a time out of 1-3 hours.
- Clear Query Cache: clear the query cache for the current data model. This cache holds the results of any previously executed queries. This cache is recommended for solutions where the same queries are executed multiple times by multiple users. It should be used with at least a time out of 3-5 minutes. The main purpose of query caching is to accelerate the re-use of the same query result set without re-querying the underlying data source for the exact same results.
Tabular
- The data model has attribute (column) level security: If this option is selected, Pyramid will retrieve the model metadata on a per user basis, restricting each user's view of available attributes as defined in the model attribute security for that user. Select this only if there is attribute (column) level security defined in the Tabular model.
Click here to learn more.
Workflows
If Custom Workflows have been enabled and custom workflow templates have been added, admins can decide how such items will be deployed throughout the app ("permissions"). If they are set to "Allow All Templates," then the templates are deployed universally. If, however, they are set to "Templates by Model," then the selection of which models will use which workflow templates is set in this panel. Since each model is secured by role and tenant, the workflows can be selectively applied with a very granular permission set.
Use the dropdown list to select which templates apply to the selected model.
- The Standard Conversations workflow always applies, unless it is fully disabled in the admin settings.
Processing
In this section you can reprocess the data model. This does not apply to externally created models or cubes (like MS OLAP, SAP BW, or HANA)
- Process Type: Before clicking the Process button, select to re-execute all the data flow and data model steps select "Master Flow." Otherwise, select "Model Only" to reprocess the data model without the data flow and manipulation processing.
- Process Now: Runs reprocessing immediately by adding it to the queue.
- Schedule Processing: Set up a schedule to reprocess the model.
- Validate Data Model: Check if the semantic data model matches the source database schema; if they are not matching, you'll be presented with any inconsistencies. You can then fix these inconsistencies from Model or from the Structure Analyzer.
Export
- Save as: Choose this option to extract and save the definition of the materialized data model, and its ETL, to the content system. This is useful if the data model's ETL was deleted or if you wish to extract the latest definition.
- Export: Export the definition of the materialized data model, and its ETL, to a PIE file.
- Delete: Delete the materialized data model. Note that the underlying database will not be deleted.
Data Catalog
- Export Data Catalog: Download the data catalog as a JSON file. The file will contain the model's tables and columns listed by the fields "type", "uniqueName", "display Name", and "description". You can add or edit the "description" field.
- Import Data Catalog: Import the data catalog after adding or editing the descriptions as needed. The descriptions will then be added to the semantic data model and will appear as tooltips in Discover.
When finished, click Apply to save your selections.
Use the two cache buttons at the bottom to clear the current metadata cache or the query for the specific model immediately.
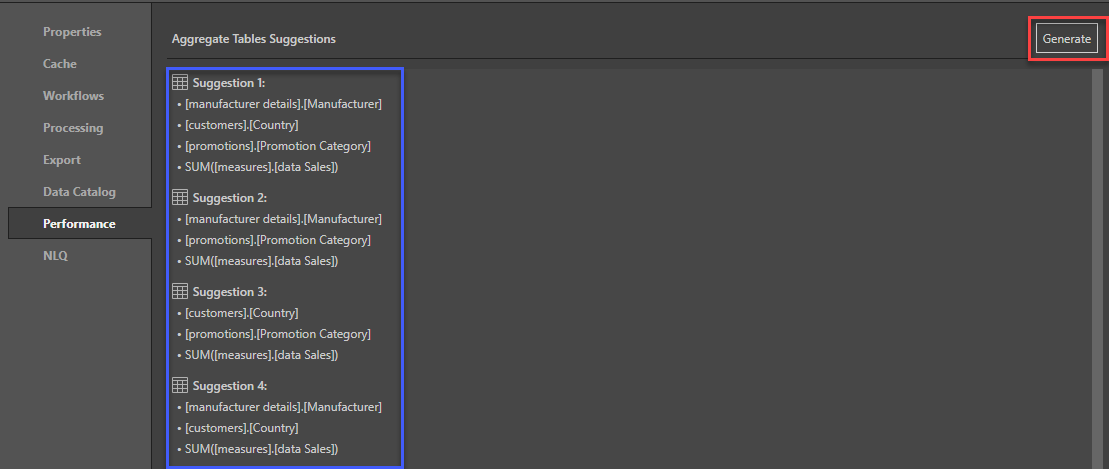
Performance
Click the generate button (red box) to create suggested Aggregate Tables using Machine Learning (ML) to analyze logs and identify frequently associated attributes and measures for the resulting tables (blue box). The database administrator can then create the aggregate tables in the database to facilitate optimized performance when executing queries requiring aggregation.
NLQ
Select an engine to use for Natural Language Queries (NLQ) that are run against this model, and create a library of synonyms to use when querying.
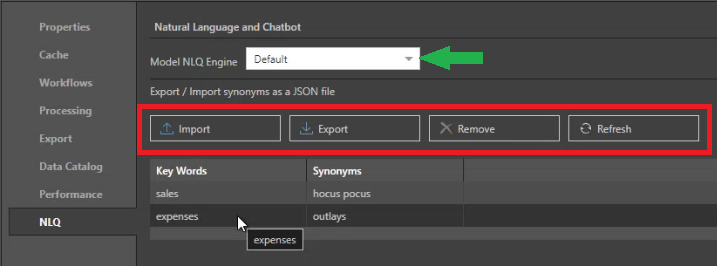
Model NLQ Engine
Use the Model NLQ Engine dropdown list (green arrow) to select the LLM Provider to use when interacting with this model using AI:
- Select System Default to use the engine selected by your administrator in the Admin Console's AI Settings.
- Select <LLM Name> to select one of the LLM Providers from your LLM Manager. Which options are available depends on the LLM Providers in the LLM Manager and your tenancy in a multitenant setup.
Synonyms
Synonyms are created by importing a list of keywords and their synonyms as a JSON file. They allow the AI to understand that different terms refer to the same objects when queries are run against this model. For example, when you run the AI Chatbot in Discover.
Note: Synonyms are alternative names for the objects in your model; this includes measure names, column names, and so on.
Use the Export / Import synonyms as a JSON file options (red highlight above) to create, manage, remove, or refresh your synonyms list. The options are as follows:
- Import: Import a list of NLQ keywords and their synonyms as a JSON file.
- Where there are multiple synonyms for one keyword, the value should be a single string that uses commas to separate each value. For example,
"synonyms":"value1, value2, value3". - When you import a new JSON, the existing synonym library is replaced in full. You should, therefore, consider exporting the existing library and then adding your new values to it to ensure that you do not accidentally lose any values.
- Your values cannot contain wildcards.
- Where there are multiple synonyms for one keyword, the value should be a single string that uses commas to separate each value. For example,
- Export: Export a list of your NLQ synonyms library to a JSON file.
- If you click Export but your synonym library does not contain any values, a JSON file containing the following is exported:
[{"keyword":"","synonyms":""}].
- If you click Export but your synonym library does not contain any values, a JSON file containing the following is exported:
- Remove: Delete your NLQ synonyms library.
- Refresh: Click Refresh to refresh your NLQ synonyms library.
The imported JSON file should be written in the following format:
[ { "keyword": "product", "synonyms": "item, offering" }, { "keyword": "expenses", "synonyms": "outlays" } ]
Tip: If you are creating a new synonym library, you might want to export the existing empty list as your first step. This exported JSON contains the first empty entries and will help to avoid making any errors.
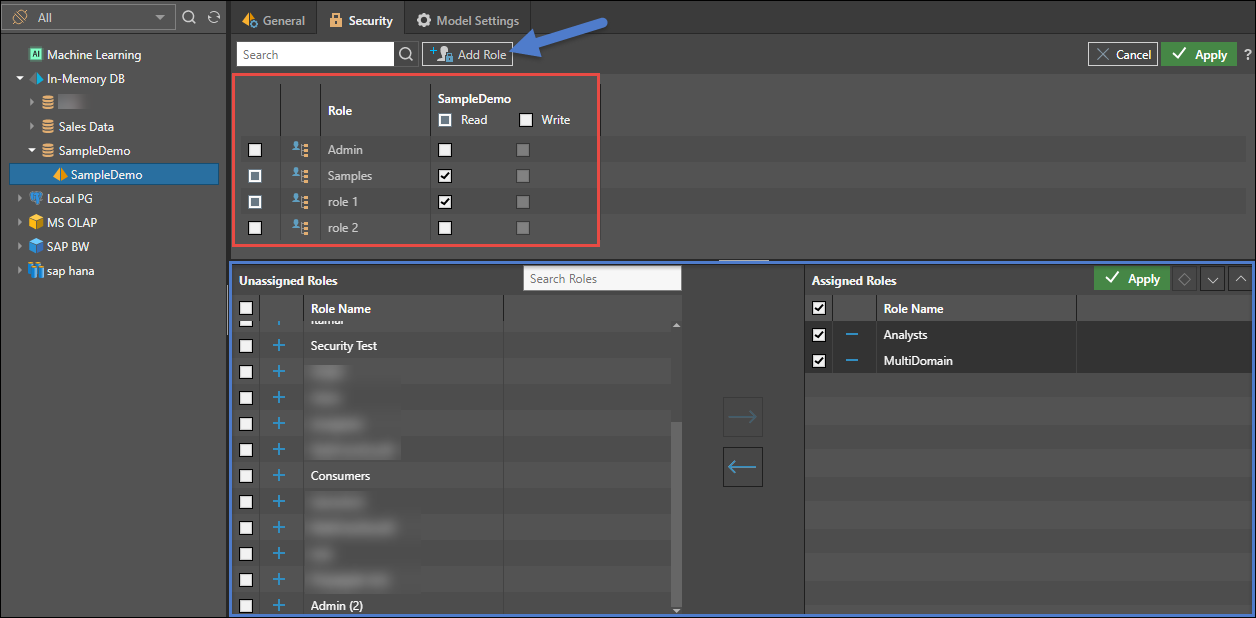
Security
For the selected data model, select the Security tab to manage access to this model by role.
- Select the roles that should be assigned to the data model.
- Read: Users will be able to query the data model
- Write: Users will be able to change the specific data model using the data modeling tools
- Click Add Role to add a new role to the list. By definition, this will propagate UPWARDS to the server and database levels as well.
Model Settings
Model Settings allow the admins to control granular elements of the model - hierarchies, measures, levels and members - for each role with access to the model.
This feature is not available in the Community Edition.
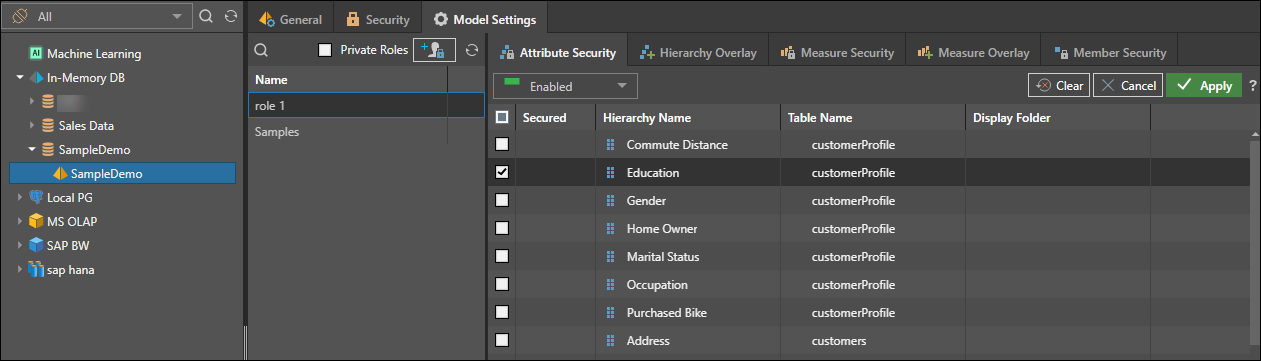
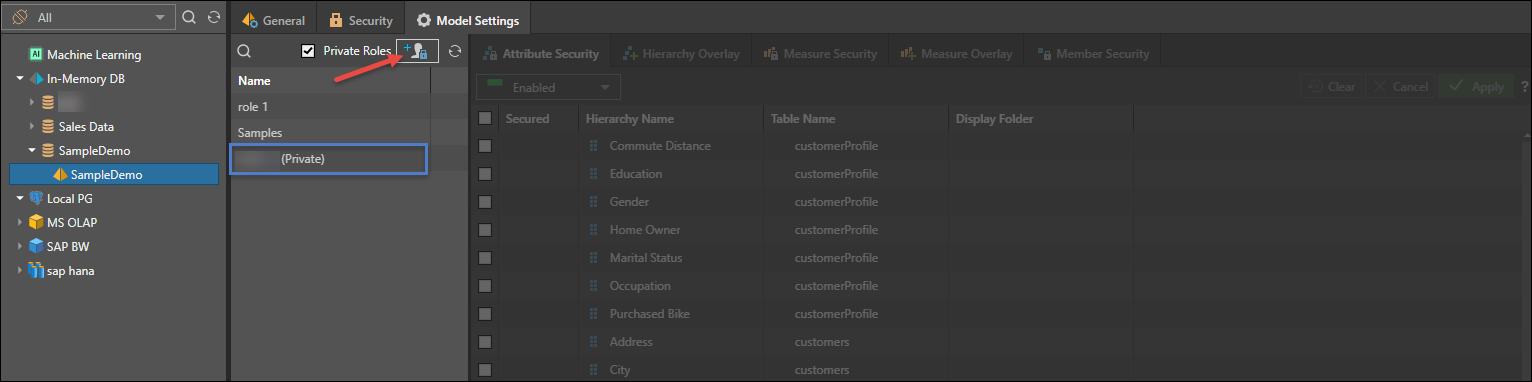
- To add more roles, click the role button. This will add a new role to the model and propagate this upwards to the database and server.
- To view private roles associated with the model, select the checkbox. This will show all users with access to the model, allowing admins to write and edit overlay rules by a specific user (although this is not recommended).
Once you've selected a role, you can set and edit the following:
- Attribute security: enable or disable roles for specified hierarchies.
- Hierarchy overlay: edit the metadata overlay for hierarchies according to user roles.
- Measure security: enable or disable selected roles for specified measures.
- Measure overlay: edit the metadata overlay of chosen measures for given roles.
- Level overlay: edit the metadata overlay of selected levels within a user hierarchy for specified roles. This is only supported for models with regular hierarchies.
- Member security: enable or disable selected member elements for specified user roles. This is not available for externally defined models (such as MS OLAP, SAP BW, and so on).