The Masking node is used to mask and obfuscate column values so that it can't be read.
Masking is an important part of the data flow pipeline for many organizations. Sometimes, due to things like government regulations or privacy concerns, it's necessary to hide protected data in test environments, so that this data is not seen by non-production users like developers, partners, customers, and so on. Examples of data that often need to be hidden include names, phone numbers, addresses, credit card details, insurance details, and more.
Materialized data maskingreplaces the original value. This means that the masked values can still be analyzed logically, even if the actual value isn't seen. For instance, say you have two columns listing staff names in 2 different tables, called 'Staff' and 'Managers'. Some employees are listed in both these tables; one such employee is 'Jane Smith'. In both tables, Jane Smith is masked as '12345abcde', meaning this employee can be analyzed logically from both tables.
To perform data masking, configure the Masking node on the relevant table; for all masked columns, the original string will be replaced by a random string of letters and numbers.
Tip: If you do not require materialized masking, but instead want to mask columns only when users with particular roles attempt to view them, you should apply Dynamic Data Masking.
Configure a Masking Node
Connect the Masking node to the Select node representing the relevant table. Go to the Properties panel and from the Masking Node window select the relevant columns from the dropdown list. Each row in the given column or columns is replaced with a random string.
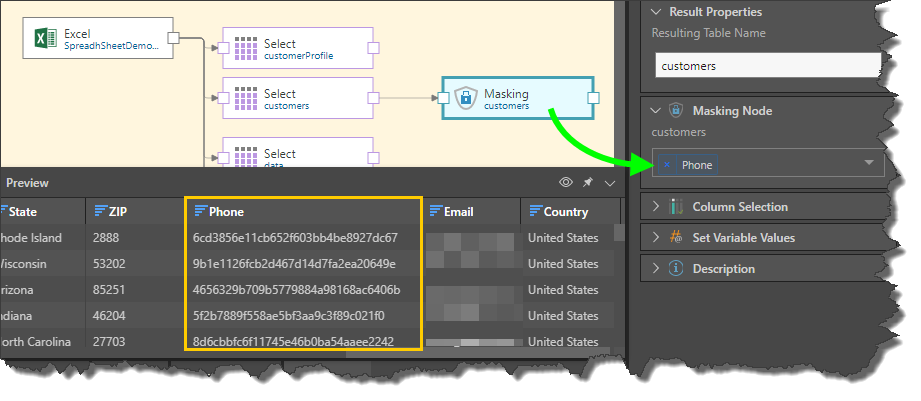
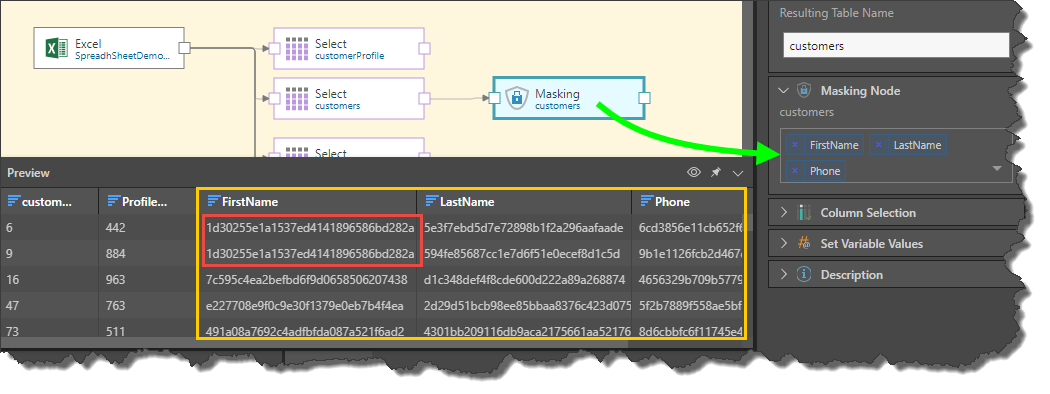
In the following example, masking is applied to the FirstName, LastName, and Phone columns. We can see that the first two strings in the FirstName column are identical (red highlight below). This is because same name appears in both these cells.
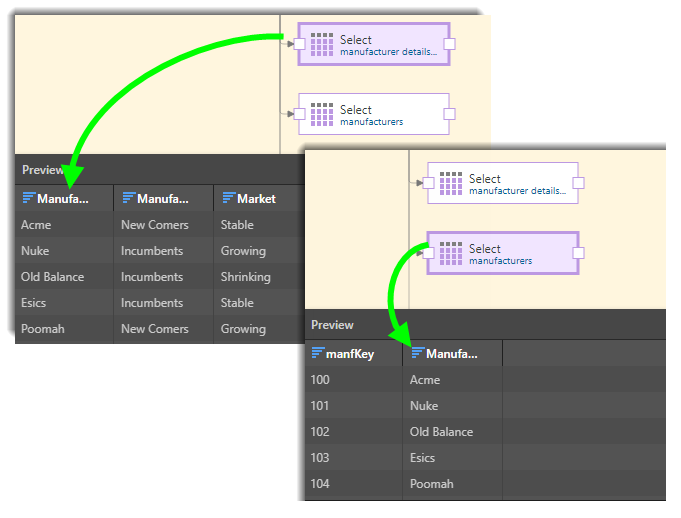
Here we have two tables that both contain the same Manufacturer column:
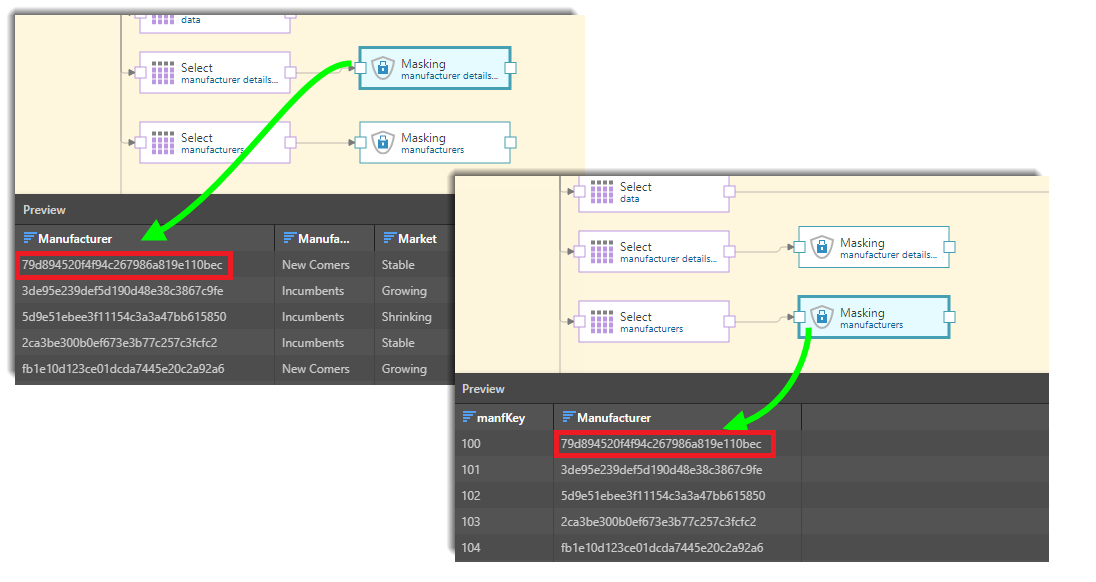
When the Masking function is applied to the Manufacturer column in both of these tables, each distinct manufacturer is assigned the same mask string in both tables:
Related information
Common Properties
There are a number of fields that are present in the Properties panel when you have any of the preceding nodes selected on the canvas. These fields include Result Properties, Column Selection, Set Variable Values, and Metadata.
- Click here for more details about the Common Properties