Pyramid enables you to connect to ODBC sources via both the ODBC node and the ODBC Direct node. The ODBC node is designed for data ingestion (copying tables from the source into Pyramid), while the ODBC Direct node is designed for direct querying (enabling Pyramid to query the data source directly, without copying any data into Pyramid).
Unlike other sources that support direct querying, the ODBC source requires a dedicated node (ODBC Direct) for this functionality. This is due to the different setup required for direct querying of ODBC sources, which requires the Admin to specify the SQL variant of the source.
- Click here to learn more about direct querying and data ingestion.
Configure the ODBC Direct Source
The process of connecting to an ODBC source is similar to that of connecting to a relational database. With the ODBC Direct node selected, choose the ODBC server to which you want to connect (yellow highlight below). If you don't see the required server in the list, click the refresh button (green arrow). Admin users can add servers here by clicking the Add Server button (orange arrow).
Once you've chosen the server, select the required database from the second dropdown list (blue highlight). The database list can be refreshed if the required database doesn't appear there (red arrow).
Enable the Use Existing Semantic Model option (purple arrow below) to create the data flow from an existing semantic model.
To enable direct querying of the data source, select the 'Direct Query Data Source node (white arrow).
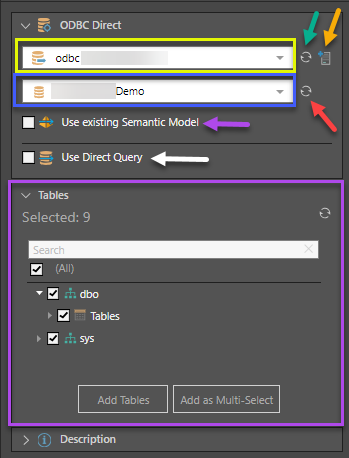
Table Selection
Once you've connected to the data source, its tables will be loaded and appear in the Tables window (purple highlight above). Select the tables that should be added to the data flow.
Direct Query
No nodes can be attached to a direct query source node. If you've enabled direct querying, you can move onto the Data Modeling stage immediately after selecting the required tables.
Data Ingestion
If direct query is not enabled, you'll need to connect the selected tables to the data flow. Select 'Add Tables' from the Tables window to assign an individual node to each table; this is important if you intend to perform any data cleansing or manipulation.
If you don't need to perform any cleansing, select 'Add as Multi-Select'; this option uses the multi-select function to copy all tables to a single node. The resulting node can be connected to a target node only.
Another way to add tables to the data flow is via the Select functions, where you can connect Table or Tables nodes. You can then input the column(s) for each select operation. Another option is to use the SQL Query node to copy a data set from the source using an SQL expression.