Upload or connect to a Text file and convert the data into a table. The Text file source supports local file upload, or pointer to a shared file on a network drive, or URL address of a text file. Both Fixed Width Column files and Delimited files are supported.
Provide the Text File
Add the Access source node to the data flow and go to its Properties panel. Start by selecting the method via which to provide the file.
Uploaded File
To upload a file, either drag and drop the file from its folder location onto the Properties panel, or click the blue Upload File button, and then find and select the file from its folder location.
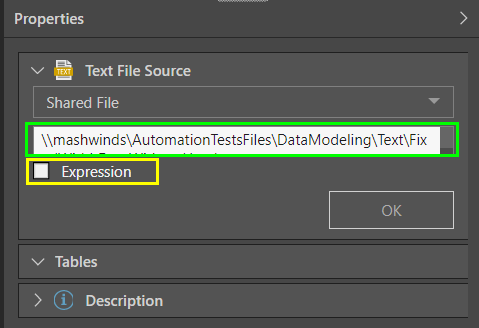
Shared File
Enter the file path of the shared file (including the file name and extension) in the File Path field (green highlight below). Enable 'Expression' (yellow highlight) to provide the file path in the context a dynamic PQL expression, created in the PQL Editor.
- Click here to learn more about connecting to a shared file.
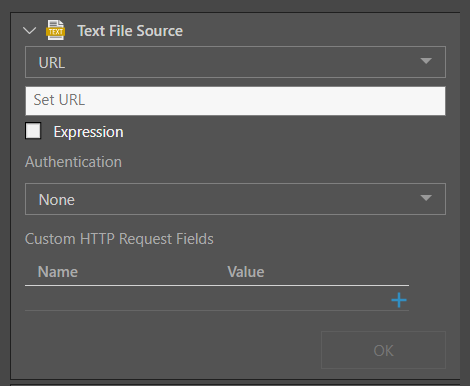
URL
The data will be downloaded from the URL when the model is processed.
To connect to an XML file via its URL, paste the URL in the Set URL field. Enable 'Expression' to provide the URL in the context a dynamic PQL expression, created in the PQL Editor.
Select the appropriate authentication type:
- None: Select None if no authorization is required.
- Basic Authentication: Select if basic authentication is required.
- Custom Header: Select if custom header authorization is required.
Configure the Text File
Once you've uploaded or connected to the file, you'll need to configure the properties to determine the structure of the table.
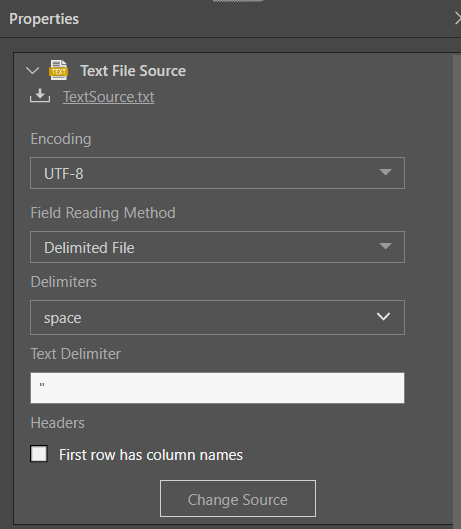
Encoding
Encoding is set to UTF-8 by default. If your text file source uses a different character encoding set, select it from the dropdown list. If you are unsure which encoding type to select, it can be seen from the bottom right hand corner of text file itself.
Field Reading Method
When using the Text File Source, you can choose from two file reading types:
Delimited File
If the text file source has delimited columns, choose this option, and then select the corresponding delimiter. If the required delimiter does not appear in the dropdown list, simply type it in the Delimiters window.
Next, confirm whether or not the first row in the file consists of column names.
Delimiters
Select the delimiter type used to separate values in the file; the given delimiter will be used to organize the values into columns. If the required delimiter doesn't appear in the dropdown list, simply type it.
Text Delimiter
Enter the text delimiter used to separate fields in the text file.
Headers
If the file's first row is made up of column names, enable'First row has column names'.
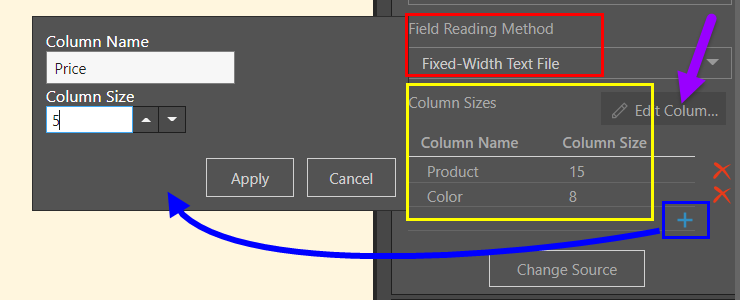
Fixed-Width Text File
If you have fixed-width text file, you must select this option as the reading method (red highlight below), and add the column names and sizes (number of characters in each column) under Column sizes (yellow highlight). You can add one column at a time by clicking the plus sign (blue highlight) then entering the column name and size (blue arrow), and clicking Apply.
You can add multiple columns at once by clicking the Edit Columns button (purple arrow).
Clicking Edit Columns will open the 'Set column names and sizes' window; enter the column names and sizes in the following format:
column,5
column,10
If you have your fixed-width columns documented, you can copy and paste them - for example, you may have an excel file which lists each column name and how many characters it is.
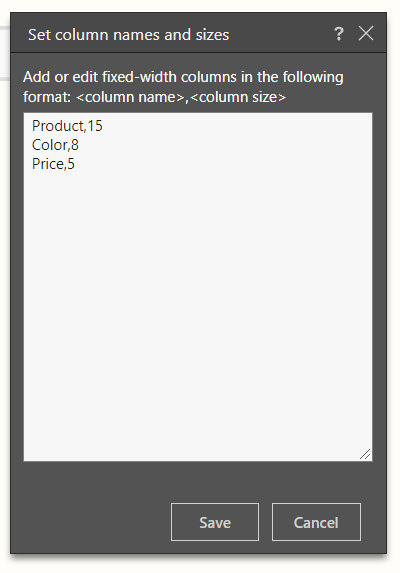
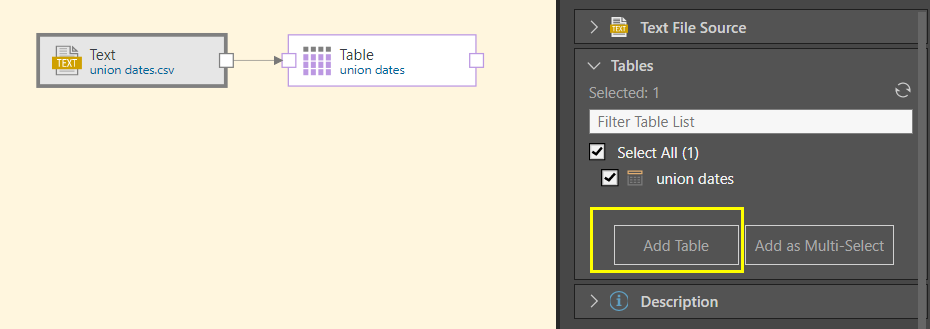
Table Selection
The XML file will be converted into a single table; select the table and click the 'Add Table' button.
The table will be added to the data flow and connected to the source node:
Description
Expand the Description window to add a description or notes to the node. The description is visible only from the Properties panel of the node, and does not produce any outputs. This is a useful way to document the ETL pipeline for yourself and other users.
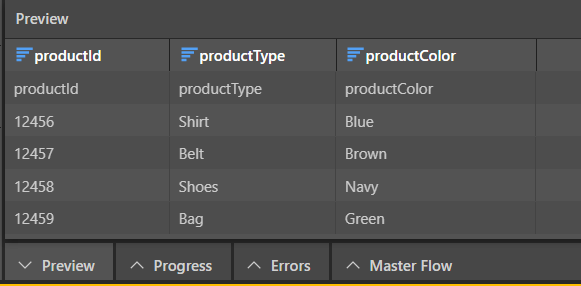
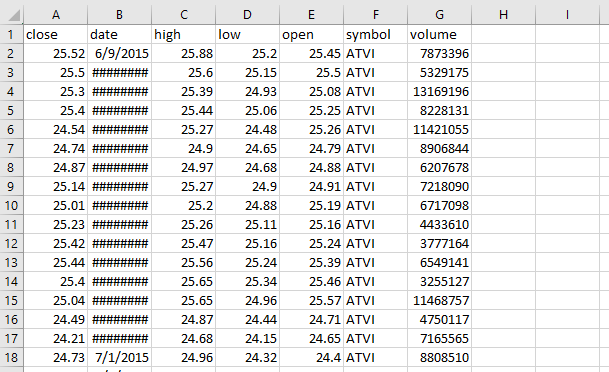
In this example we want to connect to a shared CSV file containing the following columns:
Once the shared file path is provided, the file properties must be set. Because this is a comma separated file, the reading method is set to 'Delimited File' and the comma delimiter is selected (green highlight below). And as each column contains a header, the 'First row has column names' option is enabled (yellow highlight):

Pyramid connects to the file and converts it into a table, which is then added to the data flow using the Add Table function (yellow highlight below):
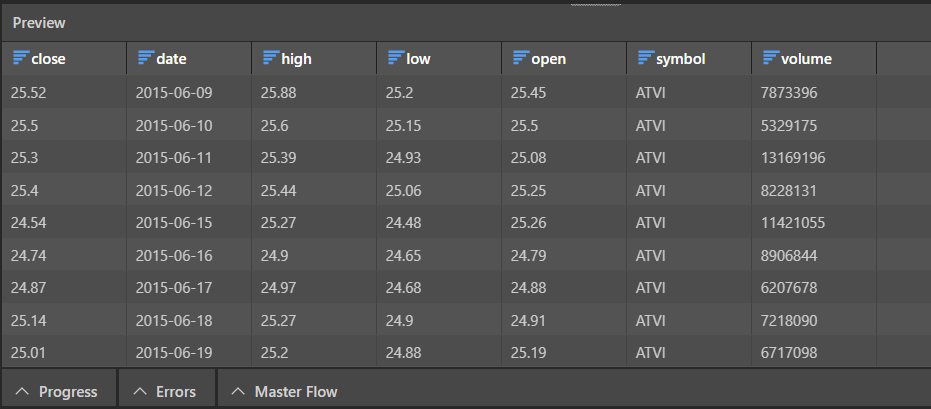
When we preview the table in Pyramid, we see that the CSV file has be converted correctly:
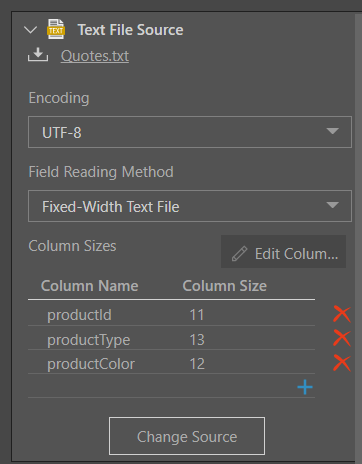
In this example, the user connected to the following shared fixed-width column text file:

Once the file path has been provided, the file properties must be set. The encoding type is set, and the reading method set to 'Fixed-Width Text File' and the column names and sizes provided:
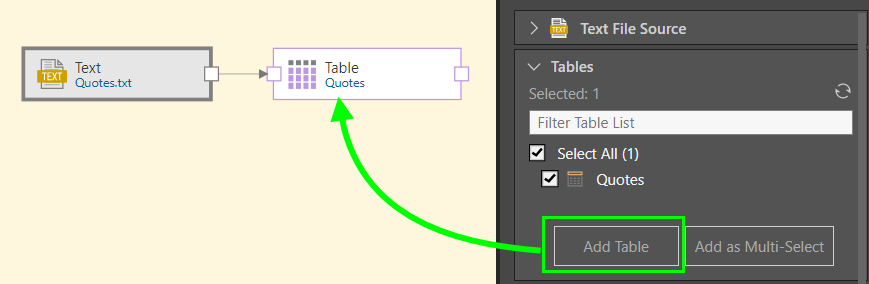
Next the table must be added to the data flow using the Add Table function:
When the table is previewed in Pyramid, it's organized into columns according to the given column size: