Parent child hierarchies are used to organize hierarchical information in the data source. Unlike level-based hierarchies, the relationships between each hierarchy level is not defined by level columns. Rather, the hierarchy structure is defined by assigning to each attribute the unique key of its parent. Parent-child structures are usually very convenient when the levels are not even (i.e. they are ragged); when the relationship between elements is a "nested" or "cork-screw" type structure; or, when the number of levels changes frequently.
- Click here to learn how to build parent child hierarchies.
- Click here for more on how to use them in Discover.
Use Cases
Parent child hierarchies are typically used for organizational data and accounting data. They are particularly useful for accounting purposes, because they enable you to define the operator for each attribute in the hierarchy. For example, you can define a minus ( - ) operator for Expenses, to ensure that expenses are subtracted from the total, rather than added to it.
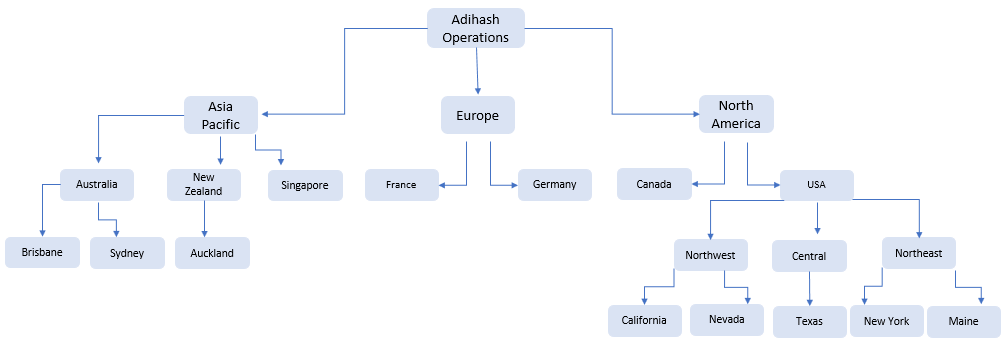
Parent child hierarchies are also useful for organizational data, particularly when the hierarchy contains an unequal number of levels, or levels that are not logically equivalent. For instance, in the example below, we see operations for the manufacturer Adihash; Adihash Operations is the top - or root - level. We see that the second level contains 3 attributes; however, the 4th level contains a different number of attributes for each region. And Australia, New Zealand, and the USA have child levels beneath them, while France, Germany and Canada don't. On top of that, this fourth level contains attributes that are not logical equivalents: under Australia and New Zealand are cities, while under USA are regions. And under USA regions is a 5th level.
So we see that the leaves (descendents that don't have children) are located at different levels of the hierarchy.
Note: This feature is only available with an Enterprise license.
Because parent child hierarchies can be updated easily, they're very dynamic. For instance, if you have an organizational hierarchy of employees, an employee who moves to a different department can be updated simply by changing her parent key. Such a change in a level-based hierarchy may require a change to every hierarchy-level column in that row.
- Click here to review examples of parent child hierarchies.
Parent Child Vs Regular Hierarchies
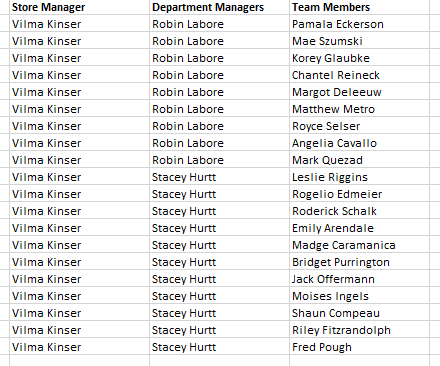
Typically, hierarchies are made up of multiple attribute columns, with each column representing a different level of the hierarchy. For example, in an organizational hierarchy for a store, you may have one column for Store Manager, another column for Department Managers, and a third column for Team Members. When these columns are used to construct a hierarchy in Pyramid, drill and expand functions will be enabled in the query so that users can traverse different hierarchy levels as needed.
A parent child hierarchy doesn't consist of discrete attribute columns in the data source. Instead, each attribute in the entire hierarchy is stored in a single column; each attribute's location in the hierarchy is defined by the unique key of its parent attribute.
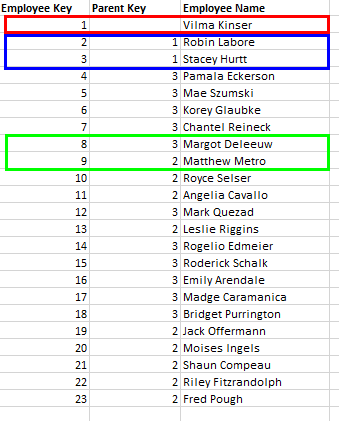
In the example below, we have an organizational parent child hierarchy for a store. The Employee Name column contains the names of the Store Manager, Department Managers, and Team Members. The employees are organized into levels using the Employee Key and Parent Key columns. Each employee is assigned an employee key; all employees that have a parent in the hierarchy are also assigned a parent key. The parent key is the unique key of the parent of the given attribute.
Vilma, the Store Manager, has not been assigned a parent key because this is the top level of the hierarchy (red highlight below). Robin and Stacey both have the parent key '1', meaning their parent is the attribute whose employee key is 1: Vilma (blue highlight). Margot is assigned a parent key of 3, meaning her parent is Stacey, while Matthew has a parent key of 2, meaning his parent is Robin (green highlight).
Unary Operators
Parent-child hierarchies have an extra capability - which is to support "Unary Operators". This is a column of indicators in the dimension source table, that indicates how each child element should be aggregated up into its parent node. This option is specifically useful in financial applications, where different items in a Chart of Accounts hierarchy are not simply additive. For example, revenue values may be pluses "+" while expense values may be minuses "-", as they roll up to Net Profit.
To use the capability, designers need to supply the unary operator column into the hierarchy's definition within the model tools.
Queries and Operators
Once a unary operator has been employed, the parent-child hierarchy logic needs to be included in every query against the model to resolve the values correctly, regardless of whether it is being used explicitly or not. This can have an effect on performance and may produce unintended consequences in highly complex semantic data model designs.
For queries across unrelated hierarchies and measure groups, while the Parent-Child Hierarchy is always evaluated in the background, the unary operator is ignored, producing the cross join total for the measure for each attribute member in the unrelated table.