Use data mapping to distribute your publication based on a dynamic list of roles or users built in the PQL editor. This differs from file mapping, where the publication is distributed to an imported dynamic list of roles or users or email addresses.
Data mapping enables users to dynamically distribute publications to a distribution hierarchy (comprising users who are the recipients of the distributed publications), based on secured hierarchies (to which the users in the distribution hierarchy have specified permissions).
- Click here for an example of data mapping.
Distribution Configuration
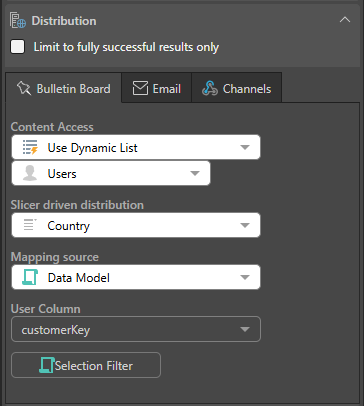
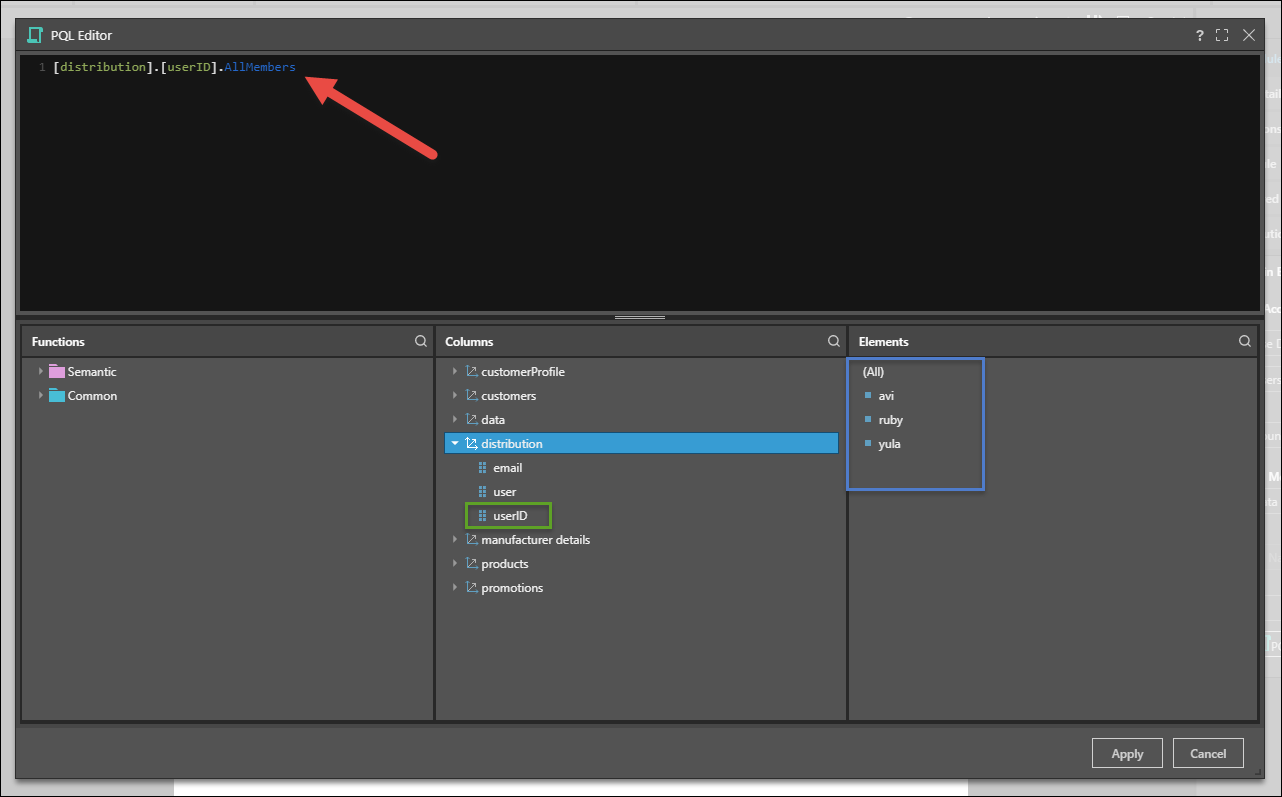
- If the slicer in the publication is from an SQL data source, create a PQL expression using Semantic or Common functions that will determine the recipients for this schedule.
- If the slicer is from an MS OLAP, Tabular, SAP Hana, or BW data source, write an MDX expression in the editor, using Semantic or VBA functions.
The expression must be based on a hierarchy of users, roles, or emails:
Distribution Tables and Columns
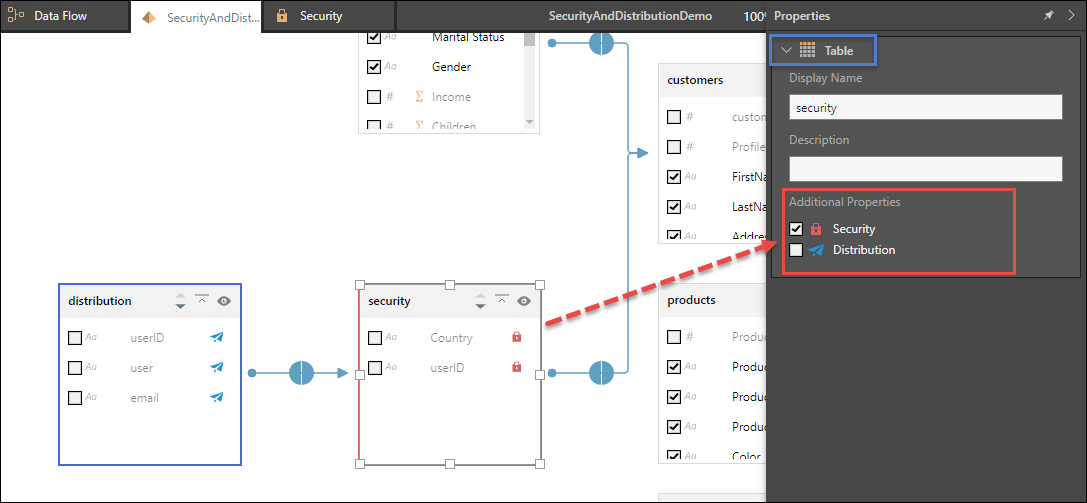
If the data model contains distribution tables or columns that you want to use to configure the distribution, you should use data mapping; the distribution tables, columns, or both will be exposed in the PQL editor.
From Model, users can mark given tables or columns as distribution tables or columns. These tables and columns are hidden from the data model and cannot be used to build queries. However, they are exposed in the PQL Editor when configuring data mapping for dynamic distribution, and can therefore be used to create the dynamic distribution list.