The JSON Extract node is used to parse and extract data from JSON (JavaScript Object Notation) columns in a table. It can be used to extract Snowflake data stored in a variant type that contains a JSON format. Users can specify the source column and can then use the auto detect function that will automatically name the new columns, detect the type and pattern required to extract the data. Alternatively users can manually add new columns by defining the pattern, data type, and name.
Extract JSON data
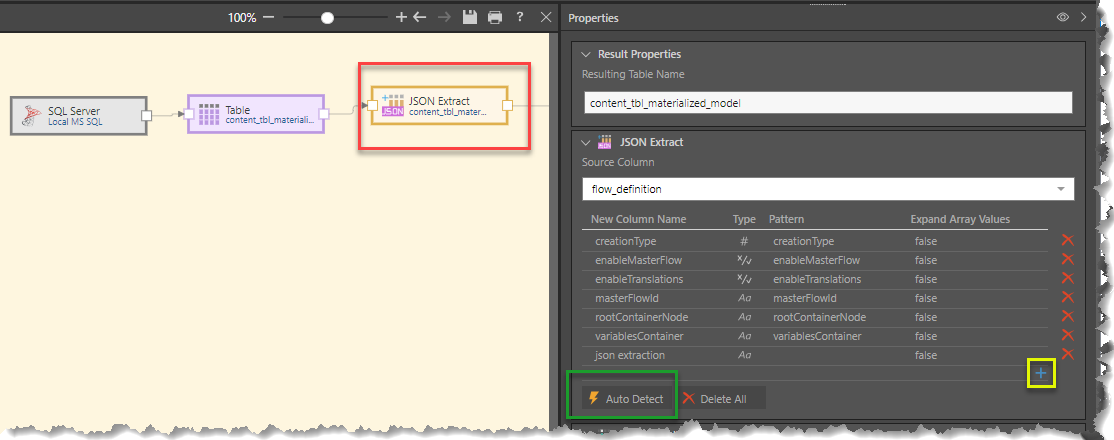
Start by connecting the JSON Extract node (red box above) to a table containing a JSON column, Go to the Properties panel to configure the node:
- Resulting Table Name: change the resulting Table Name if required, or leave it with its default name.
- Source Column: select the source column containing the JSON data.
- Auto Detect: select the auto detect button (green box above) to automatically detect all columns contained within the JSON column. All new column names, type, and pattern will be populated.
- Add New Column:Click on the '+' sign (yellow box above) to manually add a new column.
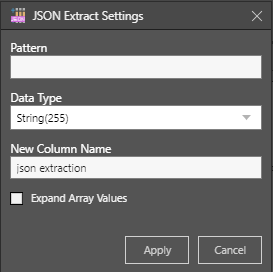
JSON Extract Settings
- Pattern: Use the label for the required element. Where arrays exist, the path name can be included in the pattern for the required element. For arrays, the array number and wildcard can also be used to extract the required element. (see examples below)
- Data Type: select the data type from the dropdown list.
- New Column Name: name the new column.
- Expand Array Values:Select this option when the field contains an array that requires extraction. The array can then be extracted by using an additional JSON extract node.
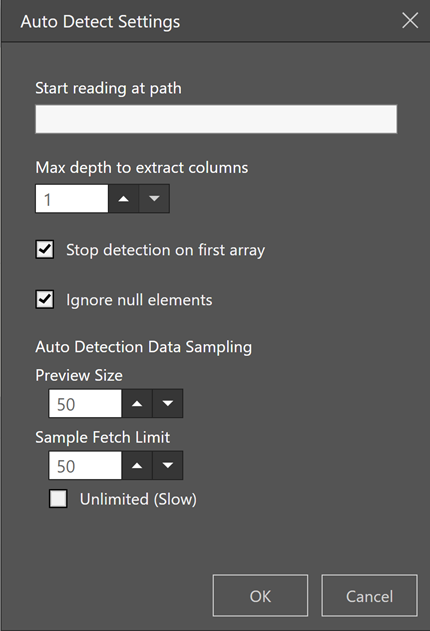
- Auto detect settings: Select this option to automatically detect all columns and data types in the json text. When selected all columns will be displayed and can be edited.
- Start reading at path: Specify the path to be used to extract the label if required
- Max depth to extract columns: Specify the number of embedded columns to search when extracting columns from the array.
- Stop detection on first array: Stop searching for additional columns if the required pattern has been found.
- Ignore null elements: Do not extract elements if they contain null. This is the default setting, but it can be overridden.
- Preview size: Define the number of rows to be displayed as a preview
- Sample fetch limit: Define the number of rows to be fetched from the table as a sample.
- Unlimited: For all records to be fetched. This could take a long time depending on the table size.
Examples: Data Extraction Examples
For the text string:
"tables":[{"inheritanceType":"ModelingTable","tableId":"6d491da9-52ff-4b0c-9a69-7ac7fa87a155","diagramLocation":{"index":0,"width" :200,"height":180,"top":20,"left":50}...}]Extract using a path name
By using tables\inheritanceType as the pattern, ModelingTable will be extracted
Use a number for the array
For the array:
"diagramLocation":{66,200,180,20,50]By using
diagramLocation \0 as the pattern, 66 will be extracted. (0 denotes the 1st position in the array)
diagramLocation \1 as the pattern, 200 will be extracted (1 denotes the 2nd position in the array)
diagramLocation \-1 as the pattern, 50 will be extracted (-1 denotes the last position in the array)
Use a wildcard
- for example where the path name is a global unique identifier - guid
For the string:
"modelingColumns":[{"63b647ab-af8f-4b11-a4ee-304362005f4a" :"Cannons",By using modelingColumns\0\* as the pattern, Cannons will be extracted
To view more details about using JSON File Sources click here.
Related information
Common Properties
There are a number of fields that are present in the Properties panel when you have any of the preceding nodes selected on the canvas. These fields include Result Properties, Column Selection, Set Variable Values, and Metadata.
- Click here for more details about the Common Properties