The Distinct node is used to remove duplicate rows from the table to which it is connected. This function finds duplicate rows in the given table, and copies only a single instance of each distinct set of rows. It defines duplicate rows as rows containing identical values in every column in the table. To define duplicate rows by comparing only specified columns, use the Remove Duplicates node.
How to Configure a Distinct Node
- Connect the Distinct node to the relevant table node.
- From the node's Properties panel, go to the Distinct Node window and click Preview to see a preview of the table with duplicate rows removed.
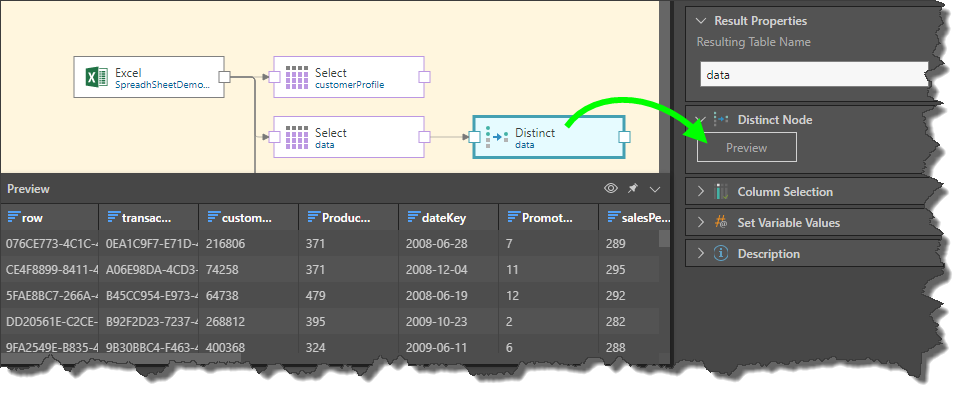
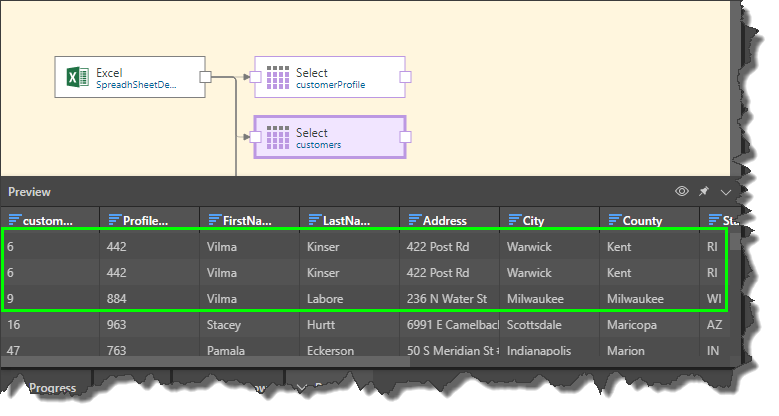
In this example, we have 2 identical duplicate rows, followed by a duplicate in the FirstName column:
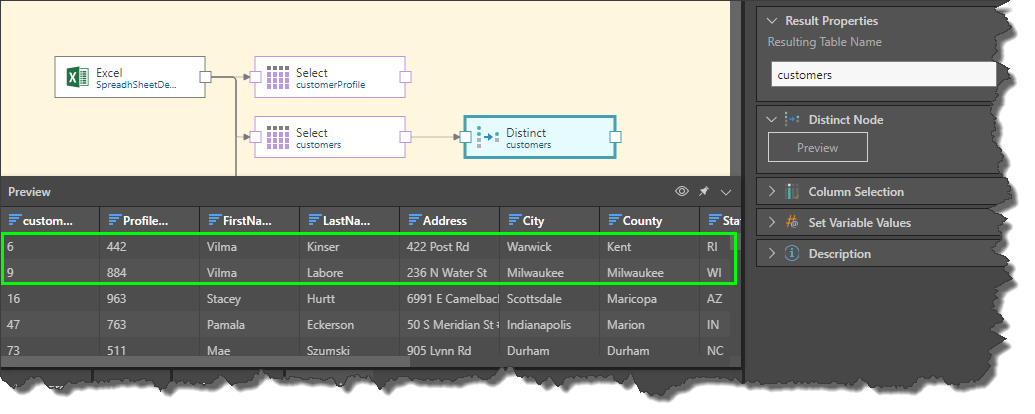
When the Distinct function is applied to the table, the duplicate row is removed, while the row containing a duplicate in the FirstName column is not affected:
Related information
Common Properties
There are a number of fields that are present in the Properties panel when you have any of the preceding nodes selected on the canvas. These fields include Result Properties, Column Selection, Set Variable Values, and Metadata.
- Click here for more details about the Common Properties