Pyramid allows you to connect to relational databases by choosing the required server and database. You can then choose to copy selected tables from the given database, or to directly query the database.
Supported Relational Databases
Pyramid currently supports the following relational databases:
- In Memory
- ServiceNow
- ClickHouse
- DB2
- DB2 AS400
- Denodo
- Exasol
- Fabric SQL Server
- Firebird
- Informix
- Maria DB
- MySQL
- Netezza
- Oracle
- PostgreSQL
- Redshift
- SAP Datasphere
- SAP Hana
- SAP Hana Cloud
- SAP IQ
- SingleStore
- Snowflake
- SQL Server
- SQL Server Azure
- Teradata
- Vertica
- Click here to learn more about connecting to a SAP Hana data source.
Connect to a Relational Database
Add a Source node
To connect to a relational database, from the Data Flow page:
- Drag and drop the relevant Source node from the Relational Sources panel onto the Data Flow canvas.
- Select the Source node on the canvas and go to the Properties panel (blue arrow above).

The preceding example shows the properties for the In Memory Source that is selected on the canvas.
Tip: If the node is grayed out in the left-hand menu (yellow highlight above), you need to create a server of this type before you can use it as a node in your data flow. You can do this by dragging the node onto the canvas, selecting it, and clicking Add Server (green arrow below) in the properties panel.
Specify Server details
From the top section of the Properties panel:
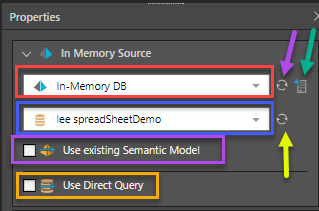
- Select the Server where the required database is stored (orange arrow). This dropdown list includes all servers of the selected source type that have been configured by an Admin:
- If you don't see your required server in the list, click Refresh (purple arrow).
- If you are an Admin user, you can add a server by clicking Add Server (green arrow).
- Choose the Database from the second dropdown list (blue arrow).
- Again, click Refresh to update the list with any recent changes.
Use Semantic Model or Direct Query
Select the Use existing Semantic Model checkbox (yellow highlight above) to create the data flow from an existing semantic model. This option allows users to build data models without having access to the underlying data source. This way, users who have restricted view permissions to certain data can still build data models.
At this point, you can either enable direct querying of the database or use the ETL tools to load a new data model into a target.
To enable direct querying, select the Use Direct Query checkbox. In this case, there is no need to create a flow diagram; instead you can progress immediately to Data Modeling to define the semantic layer of logic that determines how the database is queried.
If your data set requires manipulation or cleansing, you should opt to build a data flow diagram. To do this, do not enable direct querying.
- Click here to learn more about direct querying and data ingestion.
Table Selection
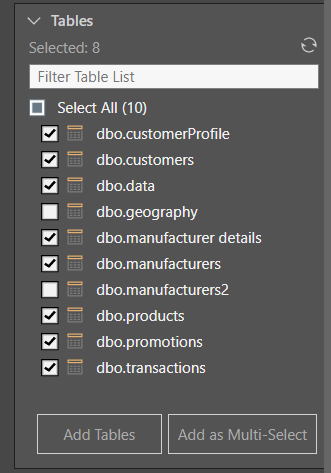
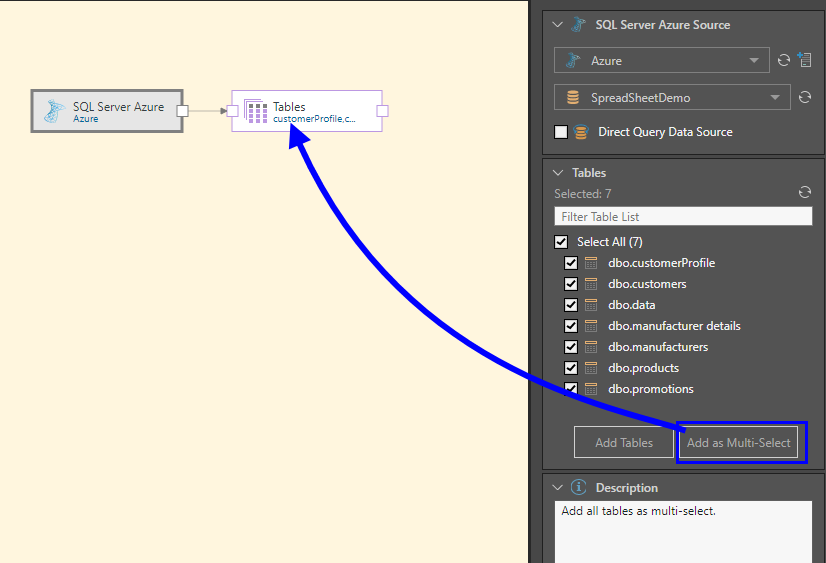
Go to the Tables panel (image below) to choose which tables to copy into the new data model. Table selection is relevant for both direct querying and data ingestion. Select the tables to copy, and then either select Add Tables to assign each table to an individual node or select Add as Multi-Select to copy all tables to a single node using the multi-select function.
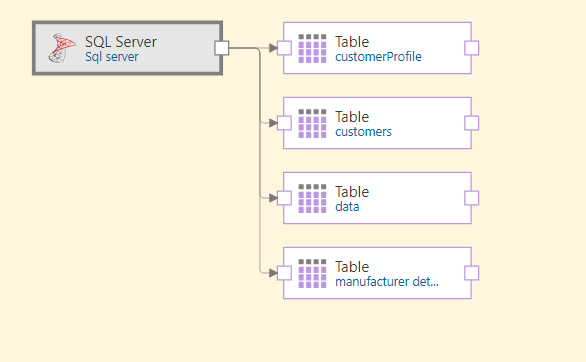
Your selected tables will be added to the data flow using the given function. In this example, the Add Tables function was used to add four tables:
Another way of adding tables from the data source to the data flow is using the Select functions. You can connect Table or Tables nodes to the source node and then input the columns for each select operation. Alternatively, use the SQL Query node to copy a data set from the source using an SQL or SOQL expression.
- Click here to learn more about the Select functions.
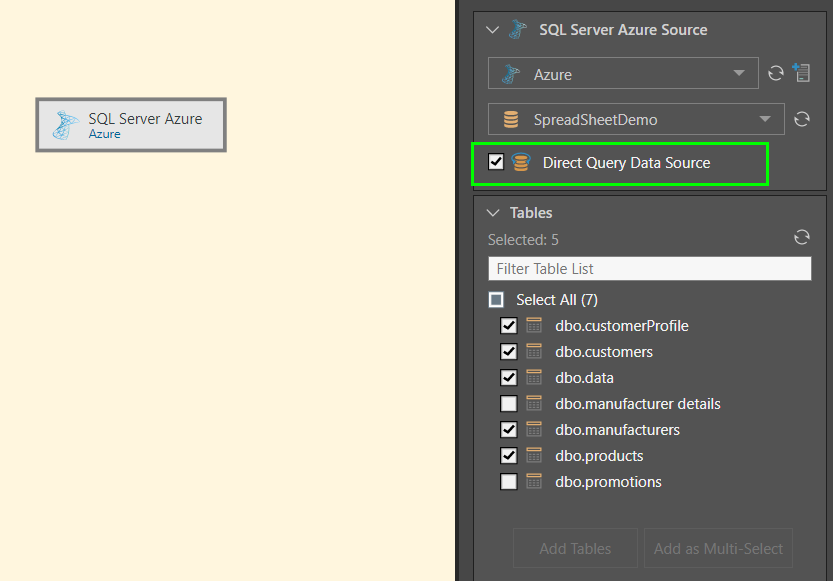
In this example, the Azure node was used to connect to a database on an Azure server (green arrow below). Five tables were then selected and added using the Table function (blue arrow). The process was documented in the Metadata window.

In this example, the Azure node was used to connect to a database on an Azure server. All tables in the database were then added to the data flow using the multi-select Tables function (blue arrow below). The process was documented in the Metadata window.
In this example, the Azure node was used to connect to a database on an Azure server. Direct querying was enabled, and then two tables were deselected from the Tables window.
Because direct querying was selected, the Add buttons in the Tables window are disabled, and the Azure node cannot be connected to any other nodes. The next step in this process is Data Modeling.