Python Scripting
Python packages are managed from the Admin console under Scripting Environments. Simply select the required environment from the relevant drop down in the Properties panel; click the Packages button see which packages have been downloaded to the given environment.
Configure the Python Scripting Node
Script
There are three ways in which you can provide the Python script:
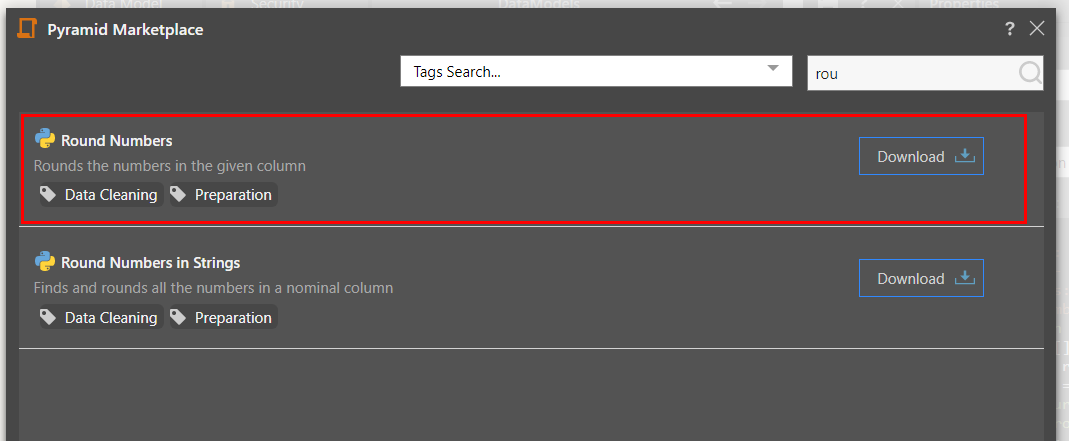
- Marketplace: download a script from the Pyramid Marketplace (red arrow below). Once downloaded, the script will appear in the script window.
- Pick a Script: open the content manager folder tree to select a script that was built and saved in Pyramid (green arrow below). Once the script is selected, it will appear in the script window.
- Write or Paste a Script: write or paste a script directly into the script window (blue highlight below).
Script Type
You can select a regular script, or a learn and predict script (orange highlight below). Learn and predict scripts are trained on a given data set, and can then be used to make predictions.
- Click here to learn about learn and predict scripts.
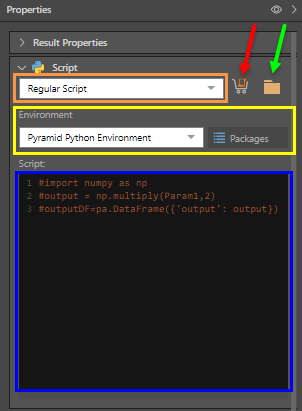
Environment
Choose the virtual Python environment that uses the required Python version and packages (yellow highlight above).
Pyramid enables Admins to create multiple virtual environments, where each of these environments can use a different Python version and different 3rd party packages.
Packages
View the list of packages that have been downloaded to the currently selected virtual Python environment.
- Click here to learn about virtual scripting environments.
Inputs and Outputs
The input window is used to configure the column(s) that will be injected into the script. The output window is used to configure the new column(s) that will be produced by the script. You can also determine whether the new column(s) will be added to the existing table (the table to which the Python node is connected), or stored in a new a table.
When you download a script from the Marketplace, Pyramid automatically detects the inputs and outputs. When writing a script of choosing a shared script, you'll need to configure the input and output columns yourself. You also have the option to use to let Pyramid auto detect the output from the script.
- Click here to learn more about scripting inputs and outputs.
- Click here to learn more about the auto detect function.
Preview
Click the preview icon from the script properties to load run the script and preview the results in the Preview panel. Any errors will be displayed in the Error panel.
In this example, the Python script 'Round Numbers' was downloaded from the Marketplace and used to round numbers in the Overhead column.
Upon downloading, it was automatically added to the Script window:
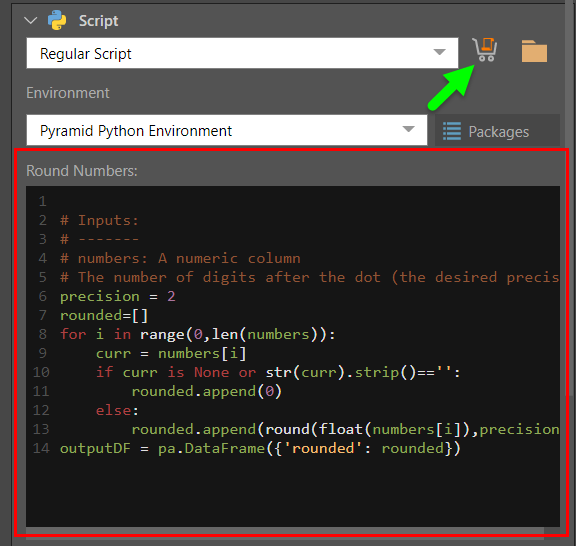
The downloaded script is as follows. Depending on the script, some objects can be changed manually if required. For instance, in this example the "precision" object determines the number of decimal places that will be returned. This is set to 2, but can be changed. If you want the column's values rounded to whole numbers, change the precision to 0.
# Inputs: # ------- # numbers: A numeric column # The number of digits after the dot (the desired precision) precision = 2 rounded=[] for i in range(0,len(numbers)): curr = numbers[i] if curr is None or str(curr).strip()=='': rounded.append(0) else: rounded.append(round(float(numbers[i]),precision)) outputDF = pa.DataFrame({'rounded': rounded})
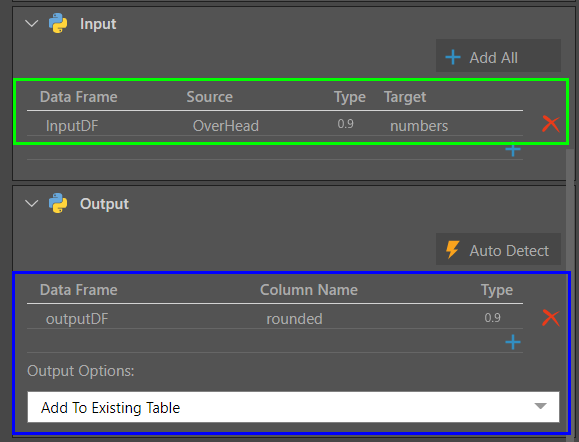
The Input and Output columns are loaded automatically when a script is downloaded from the Marketplace. However, you may need to edit the Input column(s) manually to ensure the correct columns are selected.
In this example, the OverHead column is the input, and the output is a new column called 'rounded', added to the existing table.
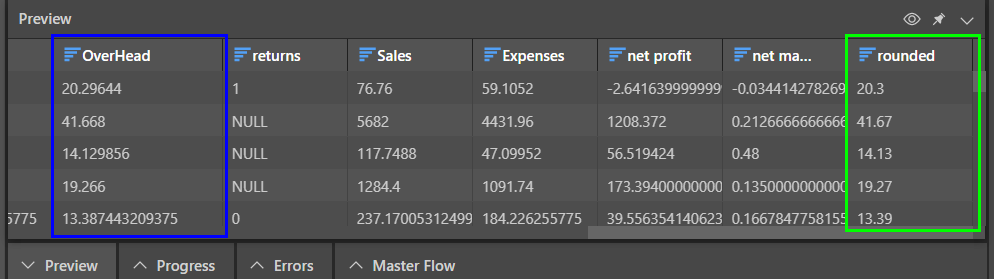
When the script is previewed, we see the table in the Preview panel. The original Overhead column (blue highlight below) is retained, and the new 'rounded' column is added (green highlight below):
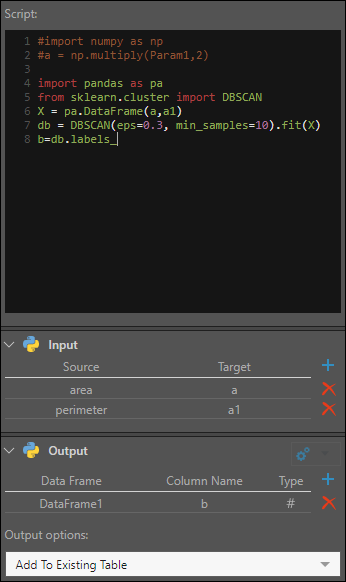
In this example, an eye-ware company wants to use DBSCAN clustering to cluster distances of their customers to each other.
They want to group data points together based on two conditions: when their distance from the other data points in the cluster does not exceed 0.3km; and when there are at least 10 data points in the cluster.
import pandas as pa from sklearn.cluster import DBSCAN X = pa.DataFrame(a,a1) db = DBSCAN(eps=0.3, min_samples=10).fit(X) b=db.labels_